netty http协议实现的抽象,对http实现是基于非servlet的异步 IO 实现。
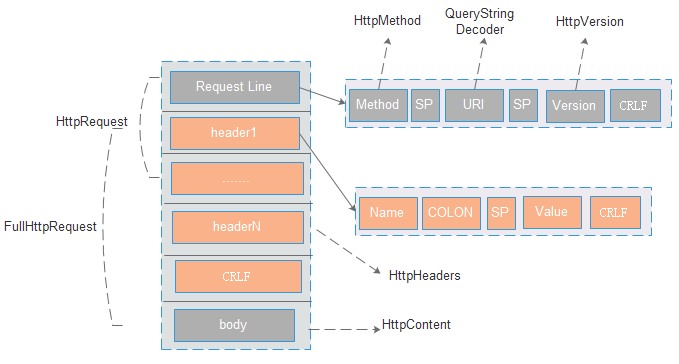
HttpMethod:主要是对method的封装,包含method序列化的操作
HttpVersion: 对version的封装,netty包含1.0和1.1的版本
QueryStringDecoder: 主要是对url进行封装,解析path和url上面的参数。(Tips:在tomcat中如果提交的post请求是application/x-www-form-urlencoded,则getParameter获取的是包含url后面和body里面所有的参数,而在netty中,获取的仅仅是url上面的参数)
HttpHeaders:包含对header的内容进行封装及操作
HttpContent:是对body进行封装,本质上就是一个ByteBuf。如果ByteBuf的长度是固定的,则请求的body过大,可能包含多个HttpContent,其中最后一个为LastHttpContent(空的HttpContent),用来说明body的结束。
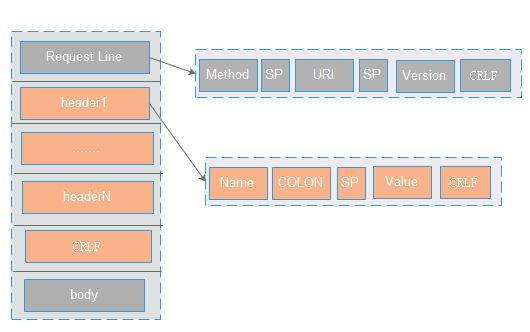
HttpRequest:主要包含对Request Line和Header的组合
FullHttpRequest: 主要包含对HttpRequest和httpContent的组合
request的流程处理,只需要在netty的pipeLine中配置HttpRequestDecoder和HttpObjectAggregator。
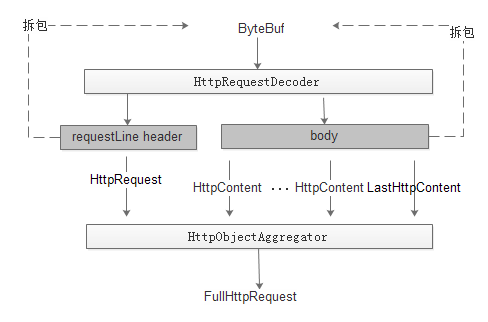
1:如果把解析这块理解是一个黑盒的话,则输入是ByteBuf,输出是FullHttpRequest。通过该对象便可获取到所有与http协议有关的信息。
2:HttpRequestDecoder先通过RequestLine和Header解析成HttpRequest对象,传入到HttpObjectAggregator。然后再通过body解析出httpContent对象,传入到HttpObjectAggregator。当HttpObjectAggregator发现是LastHttpContent,则代表http协议解析完成,封装FullHttpRequest。
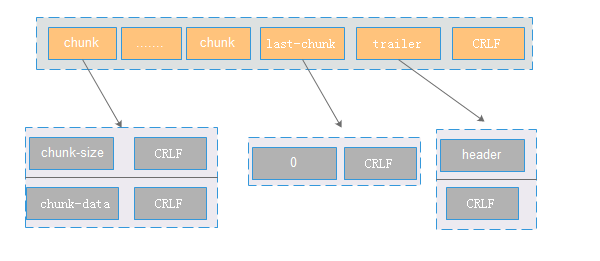
3:对于body内容的读取涉及到Content-Length和trunked两种方式。两种方式只是在解析协议时处理的不一致,最终输出是一致的。
性能优化:
1:使用堆外内存,也就是DirectBuffer。来减少GC的次数。
2:使用buffer pool,避免频繁的申请及释放内存。一般pool有两层,ThreadLocal的pool和全局的pool。 申请buffer空间时,先看ThreadLocal是否有未使用的buffer,如果没有,再从全局的pool中获取buffer。一般的内存管理策略是pool里面的buffer大小全部一致(比如1k),但是 如果需要申请2k的空间,必须要新建2k空间的buffer。如果频繁申请大于1K空间内存,则性能比较低下。 netty为了解决该问题,使用了较为复杂的内存管理策略,具体可参考 http://blog.csdn.net/youaremoon/article/details/47910971
3:零拷贝:前面提到拷贝数据的性能问题,采用零拷贝机制可有效解决该问题
CompositeByteBuf(组合): 比如读取request Line,申请1k的空间ByteBuf,如果没有发现边界(CRLF)。再申请1k的空间ByteBuf到JDK的io中读取数据。将老的ByteBuf和新申请的ByteBuf组合成CompositeByteBuf,更改CompositeByteBuf的读写指针来避免数据的拷贝。
slice(切分): 比如在1k的ByteBuf里面先读取requestLine,Header进行解析对象,最后读取body。由于body的数据还需要保存在内存里面供业务使用。一般的做法是新申请一块空间,将body的数据拷贝到新申请的空间上。这里通过虚拟一个ByteBuf,然后将读写的指针指向真实的ByteBuf的body区域上面,来避免数据的拷贝。
压缩实现,在HttpResponseEncoder之前加上 HttpContentCompressor 。response对象先进过HttpContentCompressor 压缩后,再经过HttpResponseEncoder进行序列化。
1:压缩主要是针对body进行压缩。http1.1不支持对header的压缩。
2:压缩后body的输出是trunked,而不是Content-length的形式。
Gzip格式,gzip压缩后主要包含三部分:
gzip头:主要存储的是gzip的压缩方式
deflate编码:内容采用的是deflate压缩算法
gzip尾:主要是采用CRC32算法对编码内容进行校验。
安全配置
| 参数 | 推荐 | 返回错误码 | 描述 |
|---|---|---|---|
| requst Line size | 2k | 414 | 主要是限制url的长度 |
| header size | 4k | 414 | 避免header过长 |
| body size | 60M | 413 | 此处一般和业务关联,一般设置相对较大 |
| keepalive timeout | 75 | 如果连接在设定时间内没有使用,则关闭掉连接,避免维护的连接过多 |