什么是江湖飘门律?说起来很复杂,不是三言两语能讲清楚的。是旧时代走江湖的飘门卖艺人所遵循的一条行为准则,它与官方法律不一样,事实上是超出正常法度之外的一条容忍底线。
俗话说强龙不压地头蛇,走江湖的卖艺人就算有一身功夫,也不会轻易去惹麻烦。走江湖流浪各地。对地方上的各种帮会势力,遇上了通常都要拜码头,否则在人家的地盘上不好做生意。如果受了什么欺压。一般都会选择回避或忍让,尽量不起冲突。
就算有一身好功夫,假如真起了正面冲突,生意做不成不说,在不明底细的地方对付不明底细的势力,说不定会有无穷无尽的后患。但这种回避与忍让并不是没有底线的。在什么情况下江湖飘门中人一定会动手呢?
面对欺压做出退让的选择无非是两种情况,一是你低头对方也知道收手,二是即使你低头对方也不会手软。在第二种情况下不论你怎么回避,对方都不会放过你,如果不是对手的话,那就赶紧逃走吧。如果有那个能耐,或者就算不是对手也实在躲不掉,那就出手!
这就是江湖飘门律。
至于出手的后果如何,已经没法过多的考虑了,毕竟刀已经架在眼前。而六扇门的人还没有追到身边。
分类: 日志
熵增
物理定义:熵增过程是一个自发的由有序向无序发展的过程(Bortz, 1986; Roth, 1993)。 热力学定义:熵增加,系统的总能量不变,但其中可用部分减少。
统计学定义:熵衡量系统的无序性。熵越高的系统就越难精确描述其微观状态。
早在1943年,在爱尔兰都柏林三一学院的多次演讲中,薛定谔就指出了熵增过程也必然体现在生命体系之中,其于1944年出版的著作《生命是什么》 中更是将其列为其基本观点,即“生命是非平衡系统并以负熵为生。”
人体是一个巨大的化学反应库,生命的代谢过程建立在生物化学反应的基础上。从某种角度来讲,生命的意义就在于具有抵抗自身熵增的能力,即具有熵减的能力。在人体的生命化学活动中,自发和非自发过程同时存在,相互依存,因为熵增的必然性,生命体不断地由有序走回无序,最终不可逆地走向老化死亡。
熵的定义
熵,热力学中表征物质状态的参量之一,用符号S表示,其物理意义是体系混乱程度的度量。
(1)经典热力学
1865年,克劳休斯将发现的新的状态函数命名为熵,用增量定义为![]() ,式中T为物质的热力学温度;dQ为熵增过程中加入物质的热量。若过程是不可逆的,则
,式中T为物质的热力学温度;dQ为熵增过程中加入物质的热量。若过程是不可逆的,则![]() ,下标“ir”是英文单词“irreversible‘’的缩写,表示加热过程所引起的变化过程是不可逆的。
,下标“ir”是英文单词“irreversible‘’的缩写,表示加热过程所引起的变化过程是不可逆的。
合并以上两式可得![]() ,此式叫做克劳休斯不等式,是热力学中第二定律最普遍的表达式。
,此式叫做克劳休斯不等式,是热力学中第二定律最普遍的表达式。
(2)统计热力学
熵的大小与体系的微观状态Ω有关,即S=klnΩ,其中k为玻尔兹曼常量,k=1.3807×10-23J·K-1。体系微观状态Ω是大量质点的体系经统计规律而得到的热力学概率,因此熵有统计意义,对只有几个、几十或几百分子的体系就无所谓熵。
熵的性质
(1)状态函数熵S是状态函数,具有加和(容量)性质(即对于系统M可分为M1与M2,则有SM=SM1+SM2),是广度量非守恒量,因为其定义式中的热量与物质的量成正比,但确定的状态有确定量。其变化量ΔS只决定于体系的始终态而与过程可逆与否无关。由于体系熵的变化值等于可逆过程热温商δQ/T之和,所以只能通过可逆过程求的体系的熵变。孤立体系的可逆变化或绝热可逆变化过程ΔS=0。
(2)宏观量熵是宏观量,是构成体系的大量微观离子集体表现出来的性质。它包括分子的平动、振动、转动、电子运动及核自旋运动所贡献的熵,谈论个别微观粒子的熵无意义。
(3)绝对值熵的绝对值不能由热力学第二定律确定。可根据量热数据由第三定律确定熵的绝对值,叫规定熵或量热法。还可由分子的微观结构数据用统计热力学的方法计算出熵的绝对值,叫统计熵或光谱熵。
真正的高手,都有对抗“熵增”的底层思维
原文:https://bbs.pinggu.org/thread-7046070-1-1.html
在1998年亚马逊致股东信里,贝佐斯说:“我们要反抗熵(We want to fight entropy)。”
管理学大师彼得·德鲁克说:“管理要做的只有一件事情,就是如何对抗熵增。在这个过程中,企业的生命力才会增加,而不是默默走向死亡。”
物理学家薛定谔说:“自然万物都趋向从有序到无序,即熵值增加。而生命需要通过不断抵消其生活中产生的正熵,使自己维持在一个稳定而低的熵水平上。生命以负熵为生。”
这么多人都在谈论熵,说要反抗熵,然而到底什么是熵?
什么是熵?
熵,是来自于物理学热力学第二定律的一个词。
当一个非活系统被独立出来,或是将它置于一个均匀环境里,所有运动就会由于周围各种摩擦力的作用很快停顿下来;电势或化学势的差别会逐渐消失;形成化合物倾向的物质也是如此;由于热传导的作用,温度也逐渐变得均匀。由此,整个系统最终慢慢退化成了毫无生气、死气沉沉的一团物质。
于是,就达到了被物理学家们成为的“最大熵”,这是一种持久不变的状态,在其中再也不会出现可以观察到的任何事件,它已经归于死寂。
熵代表了一个系统的混乱程度,或者说是无序程度 – 系统越无序,熵值就越大;系统越有序,熵值就越小。
所以,负熵代表着系统的活力,负熵越高就意味着系统越有序,这也是为什么薛定谔会说“生命以负熵为生”。
比如:在每周刚刚开始的时候,我们都会把房间收拾得窗明几净,可是一到周末,我们就会发现房间乱成一团。这个过程就是熵增的过程。
再比如:生命有机体在不断进行的吃、喝、呼吸以及(植物的)同化,也就是新陈代谢,正是一个对抗熵增的过程。
不要小看这个听起来非常朴素的熵定律,它在自然界中无处不在,是最基本也最重要的一个法则,化学家阿特金斯曾将它列为“推动宇宙的四大定律”之一。
它是物理学家心目中无比坚定的一个信仰,连引力公式都可以改写,但熵增定律却从未被违反。张首晟教授认为,人类的知识再往前推进,牛顿力学可能不对,量子力学可能不对,相对论可能也不对,但信息熵的公式却是永恒的。
如果将它推论至整个宇宙的发展中,我们就会发现:如果我们存在的这个宇宙之外什么都没有,也就是如果没人向这个宇宙输入能量的话,宇宙的最终结局就是走向彻底的无序,也就是死亡。
如果将它推论到企业管理中,我们就会发现:管理要做的只有一件事情,就是如何对抗熵增。如果没能有效对抗熵增,企业就会在默然中走向死亡。
如果将它推论到人生之中,我们就会发现:如果不去对抗熵增,我们的生命力就会在封闭系统内或平衡状态中逐渐变得毫无生气、死气沉沉。
那时,即使生命尚未终结,生命力也已戛然而止,也就印证了那句著名的话“很多人20岁时就已死去,到80岁才埋”。
然而,我们又该如何对抗熵增呢
对抗熵增的 人生底层逻辑
想要对抗熵增,就要引入一个非常重要的理论- 耗散结构。
“耗散结构”是由一位名叫普利高津的科学家提出的,他也因为这个理论而获得了1977年的诺贝尔化学奖。
什么是“耗散结构”?
耗散结构是一个远离平衡态的非线性的开放系统(不管是物理的、化学的、生物的乃至社会的、经济的系统),通过不断地与外界交换物质和能量,在系统内部某个参量的变化达到一定的阈值时,通过涨落,系统可能发生突变即非平衡相变,由原来的混沌无序状态转变为一种在时间上、空间上或功能上的有序状态。
耗散结构有两个最为重要的特性,一是开放性;二是非平衡。当一个系统具备了“耗散结构”后,它就能够有效对抗熵增。
那么,我们该如何依据这样两个特点将自己打造成一个可以对抗熵增的“耗散结构”呢?1
开放性
一个孤立系统的熵一定会随时间增大,当熵达到极大值时,系统就会达到最无序的平衡态,所以孤立系统绝不会出现耗散结构。
因此,耗散结构一定产生于开放系统,它必须存在着由环境流向系统的负熵流,而且能够抵消系统自身的熵增,只有这样才能使系统的熵减小,有序度增加。
维基百科与网络版的大英百科全书,都很专业,而维基百科却不需要有一群专家进行搜集编撰,它是一个开放系统,每个人都能为它贡献内容。也正因为此,它甚至拥有比网络版大英百科全书更高的传播度。
那么,我们该如何让自己成为一个开放系统呢?
1)用“成长型思维”替代“固定型思维”
很多人一直保持着这样一种观念,即我们天生有一些特定的固定不变的能力与品质,就像“我不善于运动”、“我没有学数学的天分”等,因此无法改变。
但真是这样吗?
实际上,人的智力、创造力、运动才能与其他品质,都是可以锻造的,是可以通过时间和努力去改变的。
2006年,斯坦福大学的行为心理学教授卡罗尔·德韦克出版了一本名为《思维模式:新成功心理学》的书。在这本书中,德韦克总结了自己30多年的研究成果,提出了两种思维理论:固定型思维和成长型思维。
固定型思维说的是,相信我们出生时带有固定量的才智与能力。采取固定型思维的人倾向于回避调整与失败,从而剥夺了自己过上富于体验与学习的生活。
而成长型思维则是一种以智力可塑为核心信念的系统的思维模式。它相信通过练习、坚持和努力,人类具有学习与成长的无限潜力。
拥有成长型思维的人能够沉着应对挑战,他们不怕犯错或难堪,而是专注于成长的过程。他们对于失败不害怕,因为他们知道从失败和错误中学习,它们终将变为成功。
正如科研大数据所告诉我们的:如果一个孩子拥有成长型思维,这项优势就可能消除最富有家庭与最贫穷家庭间的差距,因为成长型思维的孩子会越来越优秀。
.jpg")
从这个图表中,我们还能看到一点,也许是我们平时常常忽略的,那就是二者在对待其他人的成功这点上还有不同:成长型思维的人会将别人的成功当做自己的灵感,而固定型思维的人则会将别人的成功当做是对于自己的威胁,于是就会引发巨大的不安全感以及脆弱感。而这样一种不安全感和脆弱感,常常会让他选择堵住耳朵,闭上眼睛,于是也就切断了自我成长的渠道与途径,让整个情况变得更糟。
2)用“流量思维”代替“存量思维”
躺在书桌上的一堆油画颜料,不会自动变成一幅美妙的油画。一定是因为有了某种外界能量交换,比如,你拿起了画笔,打开了颜料,开始画画,颜料才能变成油画。
这是什么意思?
意思是说,只有在与外界交换能量之后,一个人才有可能发生翻天覆地的变化。这样的人就是有着“流量”思维的人,相反则是“存量思维”。
什么是“存量”思维者的典型行为?
相比在学习上给自己做出投资,他更愿意把钱存起来,让它产生利息;相比换个更适合更有前途的岗位或行业,他更愿意继续做现在这个安稳舒适的工作;相比将自己看到的好文章、好书推荐出去,他更愿意悄悄的收藏起来;相比与那些优秀者深入交流,他更愿意不让别人知道自己的想法。
可惜,如此一来,熵增就会加剧,危机就会潜伏。按照“熵增定律”,熵是繁荣有序的反面。然而,从表面来看,繁荣有序却是熵的隐性状态。
因此,当我们看到繁荣有序的表象时,以为熵并不存在,但实际恰恰相反,熵正在暗中窥伺。它不是不存在了,它只是隐形了。
1975年,24岁年轻的柯达工程师史蒂夫·萨松发明了世界上第一台数码相机,当他把这项惊人的成果呈现给公司高层的时候,傲慢的管理层对这个只能拍100·100像素的奇怪机器嗤之以鼻—“没有人愿意在电视上看他们的照片”,彼时的柯达在胶片时代笑傲群雄。
30十多年后,当柯达在2012申请破产保护的时候,当年的决策者们不会想到,敲响他们丧钟的正是他们自己公司发明并雪藏起来的数码相机。
历史总是惊人的相似,同样的事情还发生在了摩托罗拉和诺基亚的身上。死守“存量”,蔑视“流量”,终会带来“当下很好、未来很糟“的必然结果,而这个结果往往不是一般人能够承受的,就像清政府当年的”闭关锁国“政策一样。
2012年的时候,任正非有个非常重要的讲话,叫做《华为的2012》。
听起来他好像是在唱衰华,其实不然,他只是比较清醒地意识到华为作为一个企业,和所有其他企业一样,始终有一个巨大的威胁存在着,它就是熵。所以,任正非认为只要华为存在一天,都必须得对抗熵增。
他对华为也是这样做的:在华为的研发上做出巨额投入,比如华为2017年在研发上的投入超过900亿元的情况,研发投入占收入的近16%,这个研发的投入强度,可能比阿里和腾讯的研发投入总和都要大,更是超过了苹果。过去10年累计投入研发2400亿人民币,华为也已连续多年都是全球专利申请第一名。
从1997年开始,华为就开始持续引进来自外部的管理经验,包括IBM、埃森哲、波士顿咨询等。他们陆续给华为提供了多方面的变革,使华为在管理创新、组织机构创新、流程变革方面不断进步,奠定了华为成为一家全球化公司的根基。
这些,都是在用“流量思维”代替“存量思维”,作为一家国内知名公司,即使不做巨额科研投资,也可以既有“存量”为荣;然而,华为却并不这么想,它看到的是“流量”,是开放系统所需要的能量交换。
3)用“终身学习”代替“临时学习“,用”终身探索“代替”不再探索“
有人,每天都在学习,不论是多还是少。有人,偶尔学习一次,看一本书要用七八个月。
前者,我称之为“终身学习者”,后者,我称之为“临时学习者”。学习对于前者如同呼吸一般,对于后者则如同救急的膏药,只在受到刺激或工作需要之时,才会想起。
对于“终身学习者”而言,他通过每天学习,将自己打造成了一个开放的系统,并且能够产生复利效应。
对于“临时学习者”而言,他是封闭的体系,无力对抗熵增,也无法产生复利效应。短期内自然看不出来,但是长期来看,二者却有天壤之别。
很多人,在成年之后就不再探索了,他们停止了对于这个世界,以及对于自我的探索,他们只想走在那条早已明确的路上,按部就班的生活。但却不知,根据熵增定律,熵的阴影早已紧随其中,“中年危机”的到来也不过只是时间问题。
而那些”终身探索者“呢?
他们则很不同,他们对于这个世界、对自我、对他人,都始终有着浓烈的好奇之心,他们想要探索那些不懂的东西,想要解开那些难解的奥秘;不论是从一场电影、一次旅行、一本杂志,还是一次对话,他们都能从中探索到新鲜的信息、知识或智慧。他们就像是一些敞着口的容器,在贪婪的吸取着来自于外部世界的一切。
所以,如果想将自己打造成“开放系统”,就需要做到至少三件事:
- 第一,用“成长型思维”代替“固定型思维”。
- 第二,用“流量思维”代替“存量思维”。
- 第三,用“终身学习”代替“临时学习”,用“终身探索”代替“不再探索”。
2
远离平衡态
远离平衡态是“耗散结构”的第二个特点。
平衡态是指在没有外界影响条件下,热力学系统的各部分宏观性质在长时间里不发生变化的状态。
“耗散结构”的提出者普利高津认为,非平衡是有序之源。
那我们该怎样才能远离平衡态呢?
1)从“舒适区”走进“学习区”,甚至“恐慌区”
“舒适区”是美国人NoelTichy提出的理论,图里的3个区可以表示为你想学习事物的等级: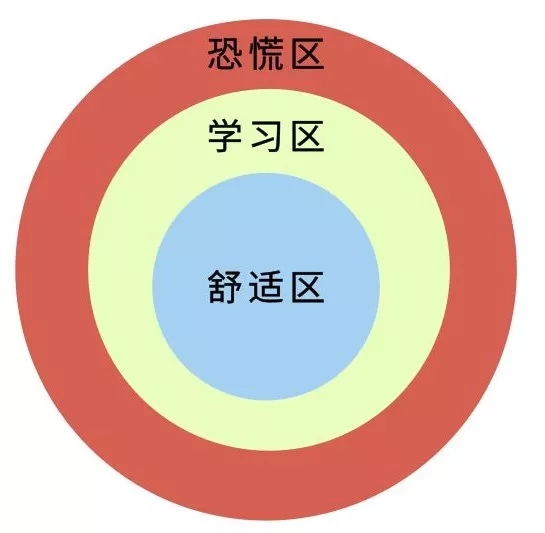
最里面一圈是“舒适区”,它代表的是对你来说没有学习难度的知识或者习以为常的事务,自己可以处于非常舒适的心理状态。
中间一圈是“学习区”,它代表的是那些对你来说有一定挑战,因而感到不适,但是不至于太难受的工作、学习、思考。
而最外一圈则是“恐慌区”,它代表的是超出你能力范围太多的事务或知识,心理感觉会严重不适,可能导致崩溃以致放弃学习。
在舒适区里,你能得心应手,因为每天都是处在熟悉的环境之中,做着自己在行的的事,和熟悉的人交际,甚至你就是这个领域的专家,对这个区域中的人和事感到非常舒适。
这就是暂时的“平衡态”,因为你无需过多努力就能使所有事物都达到一个相对平衡、比较舒适的状态。
然而,不要忘了,平衡态正是熵最大的时候。
这时,你学到的东西很少,进步缓慢,缺乏挑战和流动。这是一个看似平稳安逸,但却危机重重的状态,也就是“假性繁华”。
如果想要对抗人生熵增,按照耗散结构,你就须得远离平衡态,也就是离开那个让你感到非常舒适的区域,主动走向“学习区”,甚至是“恐慌区”。
亚马逊CEO贝佐斯就是这样做的,他将亚马逊的自营电商业务扩展到AWS云服务、FBA物流体系。而且,亚马逊在做自营电商的时候,还大胆引入了第三方卖家,让他们都在亚马逊上开店,跟自己的自营店竞争。亚马逊以网上卖书起家,但贝佐斯依然不甘心,开发出kindle阅读器用电子书打败自己的纸质书。
如果亚马逊只是停留在自己看似非常强大的自营电商业务里,在一段时间内,它当然能够获得不错的利润,达到一种稳固的平衡态。
但是,随着时间的推进,企业一定会越来越缺乏活力,缺乏创新,最终走向死亡。
正是因为贝佐斯非常清楚“熵”对于一个企业的严重危害,所以他在努力将亚马逊每一次好不容易建立好的平衡感推倒,不断把钱、把资源投入到新的领域;在企业内部创造各种形式的竞争。
也正因为此,亚马逊创造了重量级的明星业务,贝佐斯也成为了全球首富,这就是远离平衡态的巨大力量。
2)颠覆式成长
个人成长遵循的是S型曲线,在刚开始的时候,会有非常漫长的平坦状态,而后则会如火箭般骤然升空,并最终在高位保持平稳。

但这还不是颠覆式成长。
颠覆式成长不仅是一次S型曲线的飞越,它是很多次的飞越,它要求我们在完成一次S型曲线的增长后,再进入到第二条S型曲线,重新来过,不断颠覆自我。
2007年,IPOD占苹果公司收入的50%以上,iTune占74%的市场份额。按理说这正是一个产品如日中天之时,正常人的思路肯定是要继续做这个产品,用它好好赚钱。可乔布斯倒好,他要亲手颠覆掉这个已经大获成功的产品。
于是,他又做了iPhone,到2012年的时候,iPhone已经占到了苹果收入的58%,利润占到了70%。这就是乔布斯的“颠覆式成长”,他用自己做的iPhone颠覆掉了自己做的IPOD。他用一条新的S型曲线,颠覆掉了好不容易攀爬上去的S型曲线。
想要远离平衡态也是如此,需要一次又一次的走在漫长的平路上,然后跃上巅峰,在好不容易跃上巅峰之后,又要开始第二条S型曲线,就这样,不断进行自我颠覆。
而这种自我颠覆之所以很难,是因为当我们一旦到达S型曲线的上方平台,惰性就会产生。这时,是某阶段职业生涯的巅峰期,是某阶段自我发展的巅峰期,是一个看起来非常不错的状态。然而,如果一旦在这个平衡态停滞,你便不再获得成长与进步,最终的结局就是熵增加剧。
于我而言,在工作后至少做过几次非常大的颠覆式成长。
从销售部到市场部,后又从市场部到销售部;从以前在职场工作,到现在的自主工作,每一次都是颠覆式的成长。
在每一次颠覆式成长的过程中,从来都不是一帆风顺的,每次都会遇到很多的困难和阻碍,以及随之而来的孤独感与恐惧感,但得到的收获却是非常巨大的,我的人生也随之得到了极大的拓展。
那么,现在就来总结一下,两个远离平衡态的方法:
- 第一,离开舒适区,走进学习区,甚至是恐慌区。
- 第二,颠覆式成长。
这就是物理学中的熵增定律带给我们的人生底层逻辑 – 终其一生,我们都要对抗熵增,不然我们的生命力就会在默然中走向消亡。
而对抗熵增的方法就是:将自己打造成一个兼具“成长型思维”、“流量思维”、“终身学习、终身探索”、远离舒适区、能够持续颠覆式成长的耗散结构。
人类的界门纲目科属种
人类的分类:
域:真核域 Eukarya
界:动物du界zhi Animalia
门:脊索动物门 Chordata
亚门:脊椎动物亚门 Vertebrata
纲:dao哺乳纲 Mammalia
亚纲:真兽亚纲 Eutheria
目:灵长目 Primates
科:人科 Hominidae
属:人属 Homo
种:智人种(Homo sapiens sapiens)
另外,黄、黑、白种人都是同一个种,但是要细分的话还可以分出区别来,但这种区别就不是生物学上得了,所以不进行讨论(按照那种详细的分类法分的话,人种并不只有黑白黄三种,还有更多,貌似是5种,但另两种非常稀少)。
至于没有与人类同一个属但不同种的生物,可以说,以前是有的,包括:
◆卢多尔夫人(Homo rudolfensis),◆能人(Homo habilis),◆(Homo antecessor),◆直立人(Homo erectus),◆Homo ergaster(巨人、东非直立人、匠人等多种翻译),◆海德堡人(Homo heidelbergensis),◆尼安德特人(Homo neanderthalensis),◆克罗马侬人(Homo sapiens),◆弗洛里斯人(Homo floresiensis)和◆爪哇人(Homo erectus)。
但是这些都已经灭绝了,所以现在只有1种,就是智人。
另外“克罗马侬人和尼安德特人的后代存在于我们现代人之中(比如诺曼第人)”的疑问,目前学术界确实存在着一些类似的观点,认为他们应该已经通过通婚等方式和智人融合了,而不是像传统观点认为的那样单纯的被智人所取代。但是无论是传统观点还是新近的观点,两者都没有找到足够的考古学或者古生物学证据来支持自己的观点。
汉明距离
汉明距离是使用在数据传输差错控制编码里面的,汉明距离是一个概念,它表示两个(相同长度)字对应位不同的数量,我们以d(x,y)表示两个字x,y之间的汉明距离。对两个字符串进行异或运算,并统计结果为1的个数,那么这个数就是汉明距离。
汉明距离是以理查德·卫斯里·汉明的名字命名的。在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如: 1011101 与 1001001 之间的汉明距离是 2。 2143896 与 2233796 之间的汉明距离是 3。 “toned” 与 “roses” 之间的汉明距离是 3。
汉明重量是字符串相对于同样长度的零字符串的汉明距离,也就是说,它是字符串中非零的元素个数:对于二进制字符串来说,就是 1 的个数,所以 11101 的汉明重量是 4。
对于固定的长度 n,汉明距离是该长度字符向量空间上的度量,很显然它满足非负、唯一及对称性,并且可以很容易地通过完全归纳法证明它满足三角不等式。 如果把a和b两个单词看作是向量空间中的元素,则它们之间的汉明距离等于它们汉明重量的差a-b。如果是二进制字符串a和b,汉明距离等于它们汉明重量的和a+b或者a和b汉明重量的异或a XOR b。汉明距离也等于一个n维的超立方体上两个顶点间的曼哈顿距离,n指的是单词的长度。 给予两个任何的字码,10001001和10110001,即可决定有多少个相对位是不一样的。在此例中,有三个位不同。要决定有多少个位不同,只需将exclusive OR运算加诸于两个字码就可以,并在结果中计算有多个为1的位。
曼哈顿距离
欧氏距离是人们在解析几何里最常用的一种计算方法,但是计算起来比较复杂,要平方,加和,再开方,而人们在空间几何中度量距离很多场合其实是可以做一些简化的。曼哈顿距离就是由 19 世纪著名的德国犹太人数学家赫尔曼·闵可夫斯基发明的(图 1)。
赫尔曼·闵可夫斯基
赫尔曼·闵可夫斯基在少年时期就在数学方面表现出极高的天分,他是后来四维时空理论的创立者,也曾经是著名物理学家爱因斯坦的老师。
曼哈顿距离也叫出租车距离,用来标明两个点在标准坐标系上的绝对轴距总和。
欧氏距离里的距离计算:
曼哈顿距离中的距离计算:
曼哈顿距离中的距离计算公式比欧氏距离的计算公式看起来简洁很多,只需要把两个点坐标的 x 坐标相减取绝对值,y 坐标相减取绝对值,再加和。
从公式定义上看,曼哈顿距离一定是一个非负数,距离最小的情况就是两个点重合,距离为 0,这一点和欧氏距离一样。曼哈顿距离和欧氏距离的意义相近,也是为了描述两个点之间的距离,不同的是曼哈顿距离只需要做加减法,这使得计算机在大量的计算过程中代价更低,而且会消除在开平方过程中取近似值而带来的误差。不仅如此,曼哈顿距离在人脱离计算机做计算的时候也会很方便。
网络硬件卸载
OpenStack的Pike版本中引入了对switchdev的支持,实现了Open vSwitch硬件卸载offloading功能。本文简介一下网络硬件卸载。
网络Offload:
说起网络offload,主要是指将原本在内核网络协议栈中进行的IP分片、TCP分段、重组、checksum校验等操作,转移到网卡硬件中进行,CPU的发包路径更短,消耗更低,提高处理性能。
一开始这些offload功能都是在网卡上针对特定功能设计一个专门的电路并且带有很小的缓存,去做专门的事情。后来直接在网卡上部署一个可编程的通用的小型CPU,一般称为网络协处理器。就是现在的智能网卡。智能网卡的协处理器可以先对该数据包进行一些预处理,根据处理结果考虑是不是要把数据包发送给主机CPU,智能网卡中的offload功能一般是使用eBPF编程来实现的。
交换offload:
Linux 4.0引入了一个switchdev框架,它代表一类拥有“交换”能力芯片的多网口设备的抽象。其中每一个网口就是一个port,在switchdev框架中被注册成一个net_device。
switchdev起源于Open vSwitch项目,由Jiři Pirko在2014年9月首次提出。在2015年2月的Netdev 0.1会议上,网络开发人员决定扩展并采用switchdev作为硬件交换机芯片的通用解决方案。switchdev驱动模型出现之前,Linux需要交换机厂商的专门工具套件操作交换机,而在switchdev驱动模型之后,通用接口被实现,交换机正式纳入Linux网络设备体系,Linux可以用标准接口实现交换机的控制面和管理面。
架构:
在switchdev驱动框架下,硬件交换机设备上的每个物理端口都在内核中注册为一个net_device,就像对现有的网络接口卡(nic)所做的那样。可以使用现有的工具(如桥接、ip和iproute2)将端口绑定或桥接、隧道化或划分vlan。switchdev驱动程序的优点是这样的交换结构可以被卸载到交换机硬件上。因此,驱动程序将转发数据库(FDB)中的每个条目镜像到硬件,并监视其更改情况。
内核中switch架构图如下:

最初,switchdev支持的唯一设备是QEMU的“rocker”软件交换机。后来Mellanox和Broadcom等公司均提供了支持switchdev的交换机器。
OpenStack Pike版本中引入了对switchdev的支持,实现了Open vSwitch硬件卸载offloading功能。
OpenStack官方文档关于网络offload部分描述:
Supported Ethernet controllers:
The following manufacturers are known to work:
Mellanox ConnectX-4 NIC (VLAN Offload)
Mellanox ConnectX-4 Lx/ConnectX-5 NICs (VLAN/VXLAN Offload)
Prerequisites:
Linux Kernel >= 4.13
Open vSwitch >= 2.8
iproute >= 4.12
Mellanox NIC
面对职场的流言蜚语,如何正确应对
大家都是普通人,流言的困扰想必大家都经受过。办公室里是非多,时不时就传出莫名其妙的流言来,和经理出差几天回来就发现在同事眼里,你和经理已经是暧昧关系了;生病请假几天,就马上有人传言你快要跳槽了,捕风捉影,不一而足。对大多数白领而言,工作中影响心绪最多的莫过于听到这类与自己有关的流言的。
一场疫情的侵袭,让原本的氛围波澜不断,公司的不断裁员,让有些人动了歪心思,恶意制造流言,企图用伤害别人的方式保全自己,当事情发生在我们身上时候又该如何面对?
职场太无情,当你被这些流言蜚语中伤,有许多人正想看你气急败坏的失态状,并以此再次诽谤你。
面对风起云涌的职场,我们如何做到波澜不惊,内心平静不受影响,还能正确面对这些流言蜚语,避免让自己被中伤呢?坚持一些自己的原则,或许可以让你轻松一些应对。
1、不做气急败坏的冲动举动。
想要害你的人,想要中伤你的人,捏造关于你的流言蜚语的目的,也就是为了让你形象败坏,让你当众出丑,下不了台。
如果你正是因为这样的恶语,就气急败坏,生气做出一些冲动的举动,那刚巧就中了他们的圈套。
因此,在这种情况下,一定要控制自己内心的怒火,不要做出气急败坏影响自己形象的举动。
2、不做同等手段的报复。
有些人被流言蜚语诽谤,为了以牙还牙,采取同样的手段加以打击报复,而在这个报复的过程中,正是把自己从白洗到黑,反而坐实了流言。
所以,如此一来,想要清者自清的,反而是失去了自己的优势。
3、调整心态,让他们去说吧。
流言蜚语的最终目的,就是要扰乱你的阵脚,让你在工作中迷失心志,最后颇有居心的人赢得了胜利。
当我们遭受流言攻击,一定要调整心态,不要过于在乎别人的眼光和言语,看清自己的所作所为,让他们去说吧!
4、等待时间证实自己。
面对他人的流言蜚语,我们再解释,可能只会越抹越黑,无济于事反而让自己陷入更坏的境地。因此,我们要做的,恐怕也只有静待时间来洗白自己的冤屈。清者自清,在你的实际表现中,别人会看到你真实的一面,时间会证实一切。
5、职场无朋友
不要总试图和职场同事做朋友,或许大家可以和谐相处,谈笑风声;但毕竟大家是合作关系,团队有绩效,在利益面前大家又是竞争关系,很多时间不需要委屈自己来迎合他人; 职场中交友和人生中相似,古往今来都是人生得一知己足已,何况是竞争之中的职场,朋友是可遇不可求,身在职场之中我们主要的目的是用自己的劳动换取收入,这是我们劳动者的权利,没有必要委屈求全,做好自己的工作.如果环境不好我们可以更换更适合自己的环境.
职场之中大家为了各自的利益聚在一起,共同做一些事情,在人群之中能有那么一两个朋友就更好了,没有也莫自噫,守好本心,丰富完善自己,当自己的层次提升后,很多问题也许就自然解决了.
十年加老程序员给新手的几条忠告
要坚持使用一个主要开发平台,框架或语言
一旦你找到一个让你觉得舒服的平台,框架或语言,就应该坚持下去。从长远看,你期望的薪水和你的工作能力都会比频繁跳槽来得更高。找到最需要你的专属技能的好公司,然后踏实地在那里工作。我知道这听起来很简单,但我花了很多年才意识到这点。
不要为高工资追求管理角色
如果你对敲代码感到厌烦了,那么转成管理岗并不是解决方案,更好的办法是横向移动,换一个部门,换一家公司,或者是旅行,甚至可以选择在国外工作来解放你的思想,在全世界有许多技术中心,那里对开发者的要求很高,这能帮助你打开眼界。
休息一段时间
重新找回工作是很容易的,比预期的要容易得多。所以,如果你觉得自己需要的话,不要害怕一个长时间的休假。简历中的一段空白对于开发者来说不会被人认为有错。
1、保持编码( Keep coding continuously)
从长远来看,拥有个人项目、阅读、写博客和参加访谈都会有助于你成为一个更好的开发人员。只要你觉得有意思,就把你的代码推到 GitHub,并把你的经验与社区分享。
2、成为开发者社区的一员
同行聚会和进入开发群是很有趣的事情,是结识开发者伙伴的好地方。如果你想在这个行业里做到最好,就尽量不要消极被动。与坐在你旁边的人交谈,提供你的帮助,分享你的经验。每个人都喜欢谈论自己的经历,更何况你也许会遇到很多潜在的雇主。
乐意和其他开发者闲聊交谈,在那里你会碰到许多需要教练的初学者团体,你可以指导新手,给他们提供练手的机会,甚至赞助活动。
要学习别人的开发技巧并且勇于实践,要热情地欢迎不同意见的人讲话,勇敢地听取他们的意见。
3、不要在招聘网站上求职
这是智慧的结晶:不要申请那些在网站上张贴的工作职位,很多前辈大咖都在这样干
招聘网站的背后是复杂的人力资源流程、候选人跟踪系统、滥发个人简历和混乱的沟通,这也是许多公司找不到人才而要依靠猎头公司的几个重要原因。
优秀的人才应该跳过这些。网络是寻找人才之路,更多地关注当地的社区消息,当有人离开一个重要的职位,当一个有意思的公司得到了融资,或者某个企业人事变动正在招聘人时,你都会获得最新的第一手消息。
你也能通过网络社交得知哪些公司的福利比较好,各公司的大多数开发者都会真诚对待你,他们会告诉你这些公司的架构是否老旧,经理是不是人品够好,甚至工资待遇怎么样。
如果你看到一个有意向的工作机会,首先看看你的社交网,看看你的用户组或 LinkedIn 朋友圈,是否有人已经在那里工作了,或者问他们是否认识某些人。然后直接与他们联系,与那个公司的 CTO、招聘经理或其他开发人员直接交谈。
猎头是好的,但不要依赖他们。他们的任务只是帮助企业填上一个职位的空缺,因为他们并不为你工作。如果他们推荐的职位的确非常适合你所寻找的工作,那么你就去做,如果觉得不适合,那么就告诉他们:谢谢,我不去。
血色浪漫-钟跃民身边的三个女人
说说这几个女人吧。最初的主角仅仅是为了显摆,才去撩周小白,周小白是个个性鲜明的女子,她的身上有一种小资情调,这在当时是很吸引年轻小伙的。就像现在品学兼优,家境富裕,如花似玉的中学生。最受男生的爱慕。但是,周小白却有这类女生共有的缺点,大小姐脾气重,支配欲很强,眼界颇高。对于这样的女生,除非有一个男生各方面都异常优秀,又能容忍她的大小姐脾气,不然这种女性的情感经历会比较坎坷。如果说钟跃民与周小白在脾气方面还能够磨合的话,两人在人生观的差别就相当大了,一个试图将自己的人生变得丰富多彩,另一个只想安安稳稳的守着自己的男人过踏实的生活。
第二个女人秦岭,这女人像女版的钟跃民,两人的人生观有些相似,这样的两个人最合适的关系只是知己情人,而不是伴侣。他们之间,只是因为这层原因才有交集。一对长久的伴侣,要有共同的语言,有可以兼容的喜好,但最不能少的,是相互之间的责任感。而这,恰恰是两人之间最缺乏的。鈡与秦之间的感情,起于相同的爱好,更多的是从对方身上看到了自己的影子。至于为何鈡一直苦苦追寻秦的下落,其根源在于,他们在高粱垛那一次。每个男人对自己的第一个女人都是难以忘怀的,就算那女人不是个良家也一样。当然,更多的,是钟跃民对陕北生活的一种怀念。
第三个女人,高玥。有个这样的女人,真的是主角人生当中最大的福气。鈡对高的情感,可能不是爱情,却至少是一种眷恋与依靠。如果说钟跃民是风筝,高玥就是是风筝线一头的轴。任风筝飞的再高,终要被这转轴收到手心,即使风筝喜欢追逐风的脚步。高玥是个相当聪明的女人,她非常懂得把握鈡的心思。她不苛求鈡的承诺,也不需要钟跃民的细心呵护,这可以让钟跃民没有那么多的思想包袱,这是她相比于周小白的决定性优势。她可以为钟跃民置办好柴米油盐的一切琐事,让钟跃民全身心的追求他那丰富多彩的人生。她就这样,悄无声息的在这男人心底留下了一层无形的羁绊。
这么说吧,3个女人,从背景,性格,前程分析吧
1.周小白,父亲是军区首长,别人稀罕的事情在她这里就跟没事一样,性格很直接,可能跟家里最小的女儿有关系,爸爸宠着,哥哥惯着,所以看待事情起点不一样,不贴近现实的理想派,压根不知道穷苦人的生活方式以及牵挂。
2.秦岭,单亲家庭女,跟母亲一起,从小自立,所以情商高,思考的也高,身不由己也多,个人的前程就如疾风中的落叶一样,随风而走不由自个,然个人又倔强。
3.高玥,普通工薪阶层女儿,哥哥是知识分子,家里也崇尚稳定生活,所以造就她对新鲜事物和有不屈从性格的人有天生的被吸引力,个性直接,不随盲流,吸收新思想快,但本质上又是单纯的。
所以,性格决定命运。
1.周小白,注定是钟跃民一生打心眼里最稀罕的女人,但是又是最不忍心拥有的女人,她带给了钟跃民青春期的憧憬,与青涩期的骚动,但是钟跃民以当时的思想,是认定了自己与周小白是没有未来的,即使有,也是不平等不自由的未来,所以他选择放弃,反而是宁可牺牲自己一生的爱情也要保全周小白一生的感情,所以周小白注定是钟跃民一生真正爱过的女人,在内心唯一触动过的女人。
2.秦岭,与其说是钟跃民最爱的女人,不如说是钟跃民一生最想照顾的女人,因为当年一起下陕北,都等同是同一阶层的儿女,前途也是持平的,没有高低贵贱的不平搭配,而钟跃民喜欢新鲜事物,对秦岭的信天游的这种艺术,也深深折服,所以与其说他最爱秦岭,不如说是爱上了秦岭造就又给予他的一种感觉,加上秦岭把身子给了他,他也打心眼里希望这辈子能照顾秦岭,他对秦岭所有的遗憾,都来源于对自己无法实行责任的遗憾,秦岭就成了他这一生永远无法拔出的刺。
3.高玥,她不是钟跃民所爱的女人,她平凡而又不普通,她的一切特性,都是弥补了钟跃民性格上的缺失,所以她虽然不是钟跃民所爱的女人,却又是钟跃民一生最适合的女人,她的存在反而造就了钟跃民思维与故事的延续。
对于钟跃民这样的人来说,岁月会磨平菱角,但是他所做到的,就是在岁月在执行磨平人生过程中,他却在岁月的锉刀上画上了浓墨重彩的一笔,而这就是他的人生。
英衮畅人谋文明固天启
始出尚书省诗 作者:谢朓
惟昔逢休明。
十载朝云陛。
既通金闺籍。
复酌琼筵醴。
宸景厌昭临。
昏风沦继体。
纷虹乱朝日。
浊河秽清济。
防口犹宽政。
餐荼更如荠。
英衮畅人谋。
文明固天启。
青精翼紫{车犬}。
黄旗映朱邸。
还覩司隶章。
复见东都礼。
中区咸已泰。
轻生谅昭洒。
趋事辞宫阙。
载笔陪旌棨。
邑里向疏芜。
寒流自清泚。
衰柳尚沉沉。
凝露方泥泥。
零落悲友朋。
欢娱燕兄弟。
既秉丹石心。
宁流素丝涕。
因此得萧散。
垂竿深涧底。
http协议解析
http协议主要使用CRLF进行分割。
| 标示 | ASCII | 描述 | 字符 |
|---|---|---|---|
| CR | 13 | Carriage return (回车) | \n |
| LF | 10 | Line feed character(换行) | \r |
| SP | 32 | Horizontal space(空格) | |
| COLON | 58 | COLON(冒号) | : |
请求包,主要包含三部分:请求行(line),请求头(header),请求正文(body)
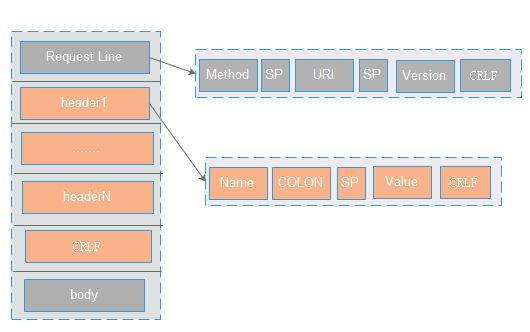
请求行(Line):主要包含三部分:Method ,URI ,协议/版本。 各部分之间使用空格(SP)分割。整个请求头使用CRLF分割。(比如:POST /1.0.0/_health_check HTTP/1.1 CRLF)
请求头(Header): 格式为(name :value),用于客户端请求的描述信息。header之间以CRLF进行分割。最后一个header会多加一个CRLF。( 比如:Connection: keep-alive CRLF CRLF)
请求正文(body) :里面主要是Post提交的数据(可支持多种格式,格式在Content-Type定义,长度是在Content-Length里面定义)。
响应包,主要包含三部分:状态行(line),响应头(header),响应正文(body)
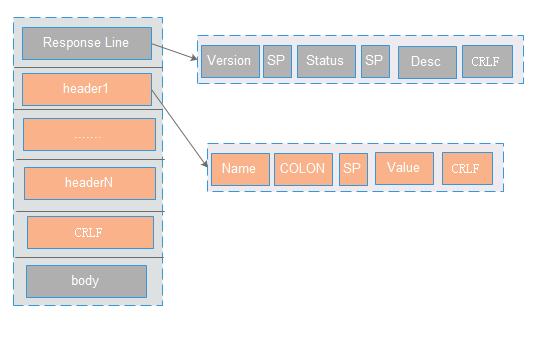
状态行(line):包含三部分:http版本,服务器返回状态码,描述信息。以CRLF进行分割。 ( 比如:HTTP/1.1 200 OK CRLF)
响应头(header) : 格式为(name :value),用于服务器返回的描述信息。header之间以CRLF进行分割。最后一个header会多加一个CRLF (比如:Content-Type: text/html CRLF Content-Encoding:gzip CRLF CRLF)
响应正文(body):里面主要是返回数据(可支持多种格式,格式在Content-Type定义,长度是在Content-Length里面定义)。
truncked协议
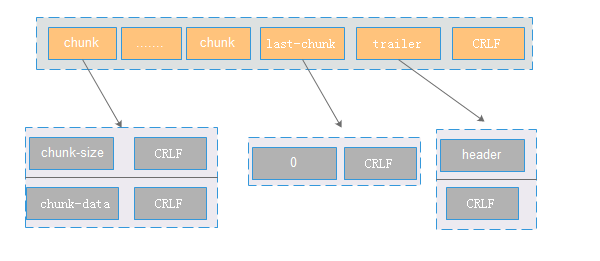
1:主要包含三部分:chunk,last-chunk和trailer。如果分多次发送,则chunk有多份。
2:chunk主要包含大小和数据,大小表示这个这个trunck包的大小,使用16进制标示。其中trunk之间的分隔符为CRLF。
3:通过last-chunk来标识chunk发送完成。 一般读取到last-chunk(内容为0)的时候,代表chunk发送完成。
4:trailer 表示增加header等额外信息,一般情况下header是空。通过CRLF来标识整个chunked数据发送完成。
HTTP协议通常使用Content-Length来标识body的长度,在服务器端,需要先申请对应长度的buffer,然后再赋值。接收数据时,发现header中有Content-Length属性,则读取Content-Length 的值,确定需要读取body的长度。
如果需要一边生产数据一边发送数据,就需要使用”Transfer-Encoding: chunked” 来代替Content-Length,也就是对数据进行分块传输。按照truncked协议分批读取数据。
压缩类型
1:压缩需要客户端,服务器端同时支持。在chrome中,请求默认会加上Accept-Encoding: gzip, deflate,客户端默认开启数据压缩。而tomcat默认关闭压缩,如果开启需要增加配置。
2:在请求时,需要通过header的Accept-Encoding: gzip, deflate 来告诉服务器客户端支持的压缩类型。
3:在返回时,http server会在返回的header中添加Content-Encoding: gzip 来告诉客户端数据的压缩方式。
4:压缩类型主要包含如下几种:
gzip 说明body采用GNU zip编码
compress 说明body采用Unix的文件压缩程序
deflate 说明body是用zlib的格式压缩的
identity 说明没有对实体进行编码。
其中 gzip, compress, 以及deflate编码都是无损压缩算法,不会导致信息损失。 gzip效率最高,使用较为广泛。
http解决粘包拆包
1:请求行的边界是CRLF,如果读取到CRLF,则意味着请求行的信息已经读取完成。
2:Header的边界是CRLF,如果连续读取两个CRLF,则意味着header的信息读取完成。
3:body的长度是有Content-Length 来进行确定。如果没有Content-Length ,则是chunked协议(具体参考前面的trunked协议)。
Android AndroidX的迁移
Google 2018 IO 大会推出了 Android新的扩展库 AndroidX,用于替换原来的 Android扩展库,将原来的android.*替换成androidx.*;只有包名和Maven工件名受到影响,原来的类名,方法名和字段名不会更改。接下来我们来看看使用 AndroidX的扩展库需要哪些配置。
1. AndroidX变化
1)常用依赖库对比:
| Old build artifact | AndroidX build artifact |
|---|---|
com.android.support:appcompat-v7:28.0.2 | androidx.appcompat:appcompat:1.0.0 |
com.android.support:design:28.0.2 | com.google.android.material:material:1.0.0 |
com.android.support:support-v4:28.0.2 | androidx.legacy:legacy-support-v4:1.0.0 |
com.android.support:recyclerview-v7:28.0.2 | androidx.recyclerview:recyclerview:1.0.0 |
com.android.support.constraint:constraint-layout:1.1.2 | androidx.constraintlayout:constraintlayout:1.1.2 |
更多详细变化内容,可以下载CSV格式映射文件;
2)常用支持库类对比:
| Support Library class | AndroidX class |
|---|---|
android.support.v4.app.Fragment | androidx.fragment.app.Fragment |
android.support.v4.app.FragmentActivity | androidx.fragment.app.FragmentActivity |
android.support.v7.app.AppCompatActivity | androidx.appcompat.app.AppCompatActivity |
android.support.v7.app.ActionBar | androidx.appcompat.app.ActionBar |
android.support.v7.widget.RecyclerView | androidx.recyclerview.widget.RecyclerView |
更多详细变化内容,可以下载CSV格式映射文件。
2. AndroidX配置
1)更新升级插件
- 将AS更新至 AS 3.2及以上;
- Gradle 插件版本改为 4.6及以上;
项目下gradle/wrapper/gradle-wrapper.propertie文件中的distributionUrl改为:
distributionUrl=https\://services.gradle.org/distributions/gradle-4.6-all.zip
- compileSdkVersion 版本升级到 28及以上;
- buildToolsVersion 版本改为 28.0.2及以上。
插件更新提示
2)开启迁移AndroidX
在项目的gradle.properties文件里添加如下配置:
android.useAndroidX=true
android.enableJetifier=true
表示项目启用 AndroidX 并迁移到 AndroidX。
3)替换依赖库
修改项目app目录下的build.gradle依赖库:
implementation 'com.android.support:appcompat-v7:28.0.2' → implementation 'androidx.appcompat:appcompat:1.0.0'
implementation 'com.android.support:design:28.0.2' → implementation 'com.google.android.material:material:1.0.0'
implementation 'com.android.support.constraint:constraint-layout:1.1.2' → implementation 'androidx.constraintlayout:constraintlayout:1.1.2'
...
4)修改支持库类
将原来import的android.**包删除,重新import新的androidx.**包;
import android.support.v7.app.AppCompatActivity; → import androidx.appcompat.app.AppCompatActivity;
5)一键迁移AndroidX库
AS 3.2 及以上版本提供了更加方便快捷的方法一键迁移到 AndroidX。选择菜单上的ReFactor —— Migrate to AndroidX… 即可。(如果迁移失败,就需要重复上面1,2,3,4步手动去修改迁移)
AndroidX 迁移
注意:如果你的项目compileSdkVersion 低于28,点击Refactor to AndroidX…会提示:
You need to have at least have compileSdk 28 set in your module build.gradle to refactor to androidx
提示让你使用不低于28的sdk,升级最新到SDK,然后点击 Migrate to AndroidX…,AS就会自动将项目重构并使用AndroidX库。
3. AndroidX迁移问题
《Android Support库和AndroidX冲突问题》
4. AndroidX影响
虽然说目前对我们没有多大影响,我们可以不使用仍然使用旧版本的支持库,毕竟没有强制,但长远来看还是有好处的。AndroidX重新设计了包结构,旨在鼓励库的小型化,支持库和架构组件包的名字也都简化了;而且也是减轻Android生态系统碎片化的有效方式。
参考
三生有幸遇见你纵使悲凉也是情

三生有幸遇见你纵使悲凉也是情是什么意思:
1、不论结局如何,很高兴能认识你
2、很庆幸能够与你相遇,与你相识,与你相知,并与你相爱。今生有你,不论在一起会遇到什么样的困难,甚至离别,都不会后悔,情之所至。

三生有幸遇见你下一句是什么:
1、三生有幸遇见你,纵然悲凉也是情,知卿心系在我心,不枉今生爱一场!
2、大千世界,处处繁花似锦,能够遇见你三生有幸。
3、三生有幸遇见你,人生只有两次幸运就好,一次遇见你,一次走到底。
4、醒时捕光,睡时捉梦 ,不如遇见你三生有幸。
5、城南小陌又逢春,只见梅花不见人。
人有生老三千疾,唯有相思不可医
本是青灯不归客,却因浊酒恋红尘。
三里清风三里路,步步风雨再无你。
终是庄周梦了蝶,你是恩赐也是劫。
三生有幸遇见你,纵使悲凉也是情。
6、三生有幸遇见你,十里桃花马蹄急; 只闻锦瑟风乍起,但将心事付瑶琴。
7、道生一,一生二,二生三,三生有幸遇见你。太极生两仪,两仪生四象,四象生八卦,八卦衍万象,万象不如你。
8、三生有幸遇见你,一直相随永不弃。
9、三生有幸遇见你,无关风月也是情。
10、听一曲风声,画两道身影,说三生有幸遇见你。
Centos7 切换 GCC 版本
查看gcc版本是否在5.3以上,centos7.6默认安装4.8.5
gcc -v升级gcc到5.3及以上,如下:升级到gcc 9.3
yum -y install centos-release-scl yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils scl enable devtoolset-9 bash 需要注意的是scl命令启用只是临时的,退出shell或重启就会恢复原系统gcc版本。 如果要长期使用gcc 9.3的话:
echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
这样退出shell重新打开就是新版的gcc了
以下其他版本同理,修改devtoolset版本号即可。
世道与人心
两个不同故事,同样的选择,简明解释世道与人心
故事1:一个富二代看下一个穷姑娘,假装穷小子接近,后来成为情侣, 有一天男子家境暴漏
故事2:一个穷小子看下一个穷姑娘,假装富二代接近,后来成为情侣, 有一天男子家境暴漏
姑娘的选择:A)我不在乎钱,只想和他一起 B)渣男,欺骗我感情,分手
故事1,多数选 A 这就是世道
故事2,多数选 B 这就是人心
IDEA2019.3安装和激活
之后进到这个界面,点击 Configure -> Edit Custom VM Options
在最后加上 -javaagent:/data/jetbrains-agent.jar
这个jar包是需要用来破解的jar包: https://files.cnblogs.com/files/quyf/jetbrains-agent.zip
IntelliJ IDEA 破解之后,用了一段时间后,打开软件提示 no suitable licenses left on the license server
需要让我们重新注册,原来是之前的地址服务更改为了新的地址: http://fls.jetbrains-agent.com
所以我们在使用服务器激活的时候使用新的地址代替原来的地址即可:http://jetbrains-license-server/
沟通难四个原因
《PMBOK 指南》将沟通管理划为一个专门的知识领域,建议项目经理花 75% 以上的时间在沟通上。根据美国普林斯顿大学的调查报告,在所有对工作产生影响的因素中,沟通占的比例高达 75%。而我们工作中出现的 80% 问题都是由沟通不当造成的,可见沟通的重要性,因为沟通实在太难了。多数时候,我们只想着表达自己的观点,只关注自己想说什么,我们会尽量使用漂亮的 PPT、华美的语言、一堆的数据、甚至引章据典,而不关心别人听懂没有,没有思考别人是否想听,别人是否听得懂。
沟通难主要出于以下四个原因:
第一种是由于立场、利益、背景的原因,当双方缺乏信任,或处于敌对状态时是无法沟通的,这个时候的沟通和所说内容的对错没有必然的关系,对方只想找差错,找到了就会理解为阴谋论,并且非常兴奋,所谓道不同不相为谋。这是最困难的沟通场景,越沟通,矛盾分歧会越大,实际是无效沟通。在公司中,经常会因为组织架构设计的不合理,造成团队利益的冲突,从而产生很多的无效沟通。
第二种是由于语言、专业知识、职位、环境的巨大差异,造成沟通方面的巨大鸿沟,本质上是思维方式、常识、知识储备的不一致造成的认知差异,这样的沟通成本非常巨大,需要恶补相关知识,参加专业培训消除鸿沟才能够创造沟通的条件。
第三种是由于沟通信息衰减造成的,语言文字是我们主要的沟通方式,但是很多时候光靠语言文字会有歧义,比如我们对名词概念的理解可能会有不同,甚至可能会完全相反,对语言中所带情绪的理解也不同,而这些都会造成信息的压缩。有研究表明,对话沟通中语言起到的作用仅占 38%,而肢体语言所占的比例高达 55%。你想表达的意思和你说出来的话语会有差异,对方听到的信息和对方理解的意思又会有差异,这就形成了我们通常说的沟通漏斗:
第一个漏掉 20%:你想表达的是 100%,实际表达的只有 80%,主要原因有语言词汇的限制等;
第二个漏掉 20%:听者只接收了 60%,主要原因有信息衰减、听得不仔细等;
第三个漏掉 20%:听者只理解、听懂了 40%,主要原因有词语理解能力、注意力不集中等;
第四个漏掉 20%:最后听者只记住了 20%,主要原因是没有反馈、容易忘记等;而随着时间的推移,如果不持续做交流沟通,最后的 20% 也会被忘记。
第四种沟通障碍是沟通交流者的心态,这个又和企业、团队的组织架构及文化有关,以下举例一下可能存在的心态对沟通的影响:刚刚进入
充满信任的技术团队
LinkedIn 首席执行官杰夫·韦纳(Jeff Weiner)认为,“在时间的流逝中保持一致就是信任”,这个“一致”有很多含义,如目标的一致、行动的一致等;微软首席执行官萨提亚·纳德拉(Satya Nadella)认为,“信任 = 同理心 + 共同价值观 + 安全可靠”,他把“同理心”放在了信任等式的第一位,认为无论做什么事情,都需要大家对所做的事情产生共鸣。
团队合作中,每个成员的工作多多少少都会和其他人有一些上下游交互,如果上游的人总是能够对下游人的诉求快速响应,无疑会让下游的人感觉更加安心。以我们的交付团队为例,我们有专职的集成测试团队,他们要负责软件发布前的最后一轮验收,但是开发团队的交付延迟总是会把集成测试团队搞得手忙脚乱,团队内的相互指责也从来没有停止过。后来,我们引入了统一研发看板系统,使得每一个员工的任务都在看板上可见,任何下游的同事都可以看到其依赖的上游员工的进展和潜在的风险。通过这套实时反馈系统,下游员工可以提前了解风险,以便及时采取应对措施,那种一无所知的不信任感很容易就消除了。可见,员工之间要及时进行沟通,才能及时获取自己关切的信息,团队人越多,沟通效率越低,越要想办法增加沟通的带宽,而构建可以透明呈现所有人信息的系统是一个不错的实践。
1994 年,心理学家 Freeston 等人提出了“无法容忍不确定的程度(The Intolerance of Uncertainty)”这一概念,简称 IU。一系列研究认为,IU 是担心、焦虑产生和维持的关键影响因素,也是焦虑及焦虑障碍的最重要预测指标。对于不确定的焦虑,会影响我们的知觉控制水平,也就是我们所感知到的“自己能够在多大程度上影响事情的结果”。当我们对不确定的焦虑越高时,我们就会越不相信自己能够影响事情的结果,对自己的贡献就会越不信任。
广告名词 CPA、CPS、CPM、CPT、CPC 、CVR、OCPC、OCPM是什么
1.CPA(Cost Per Action) 每行动成本,这个行为可以是注册、咨询、放入购物车等等。CPA是一种按广告投放实际效果计价方式的广告,即按回应的有效问卷或注册来计费,而不限广告投放量。电子邮件营销(EDM)现在有很多都是CPA的方式在进行。
2.CPS(Cost Per Sales):以实际销售产品数量来换算广告刊登金额。CPS是一种以实际销售产品数量来计算广告费用的广告,这种广告更多的适合购物类、导购类、网址导航类的网站,需要精准的流量才能带来转化。
3.CPC(Cost Per Click) 每点击成本。CPC是一种点击付费广告,根据广告被点击的次数收费。如关键词广告一般采用这种定价模式,比较典型的有Google广告联盟的AdSense for Content和百度联盟的百度竞价广告。
4.CPT(Cost Per Time) 每时间段成本。CPT是一种以时间来计费的广告,国内很多的网站都是按照“一个星期多少钱”这种固定收费模式来收费。这种广告形式很粗糙,无法保障客户的利益。但是CPT的确是一种很省心的广告,能给你的网站、博客带来稳定的收入。阿里妈妈的按周计费广告和门户网站的包月广告都属于这种CPT广告。
5.CPM(Cost Per Mille) 每千人成本。CPM是一种展示付费广告,只要展示了广告主的广告内容,广告主就为此付费。这种广告的效果不是很好,但是却能给有一定流量的网站、博客带来稳定的收入。有人认为,CPM的计算不能按照被看到作为衡量标准,如果一个Banner在页面底部,需要滚屏才能看到,只要这个Banner在该页面中被展示了1000次,即使1000次中没人滚屏到页面底部看这个广告,也应该计算为一个CPM。

(1)CPT和CPM只在第一步收取广告费用,即媒体只需要将广告对广告受众进行了展示,即可向广告商收取广告费用。
(2)CPC只收取第二步费用,消费者看到广告后并进行了点击行为以后,媒体向广告商收取广告费用。
(3)CPA和CPS处于第三步,即消费者有看到广告后并点击了广告,进一步了解活动情况后在广告主的网站完成某些特定行为(例如付款消费,填表注册等)。

相比而言,CPM和CPT对网站有利,而CPC、CPA、CPS则对广告主有利。目前比较流行的计价方式是CPM和CPC,最为流行的则为CPM。
从广告价格上来分,CPT和CPM的表面价格相对较为低廉,而CPC居中,CPA和CPS的价格则似乎要高很多。需要指出的是,这里说的价格只是表面价格,不等于性价比。一般情况下,CPA和CPS的性价比相对固定,而CPC和CPT、CPM则根据网站对用户的粘性不同而有区别。
从作弊难易程序来看,CPT和CPM的选择,通常取决于网站的质素,而网站的质素,衡量标准似乎只有网站统计和第三方统计,但这些都是很容易作弊的,国内满天飞的刷流量软件和网站,就是CPT和CPM作弊的最佳工具,尽管站长们都知道,但是广告商却只能在一段时间内广告效果不如意时才能有所察觉。
对于CPC广告,尽管存在一定的技术防范措施,作弊也相对容易,国内甚至有网站出售点击广告包月,这也是导致国内CPC广告联盟式微的原因吧。而CPA也相对较为容易,只要有足够多的时间和精力去注册和验证虚假用户。唯CPS广告几乎不在乎作弊,也是几个广告类型中唯一很难作弊的广告模式。

1.CVR (Click Value Rate): 转化率,衡量CPA广告效果的指标
2.CTR (Click Through Rate): 点击率
3.ROI: Return On Investment,投资回报率,或者说 投资利润率。指通过投资而应返回的价值,它涵盖了企业的获利目标。利润和投入的经营所必备的财产相关,因为管理人员必须通过投资和现有财产获得利润。又称会计收益率、投资利润率。