mount -v -t cifs -o umask=文件权限掩码,uid=用户uid,gid=用户组gid,iocharset=utf8,username=服务器用户名,sec=ntlmssp //服务器ip/共享的文件夹 挂载点
uid和gid是挂载到本地后本地用户的uid和gid
mount -v -t cifs -o umask=文件权限掩码,uid=用户uid,gid=用户组gid,iocharset=utf8,username=服务器用户名,sec=ntlmssp //服务器ip/共享的文件夹 挂载点
uid和gid是挂载到本地后本地用户的uid和gid
内存共享: 两个不同进程A、B共享内存的意思是,同一块物理内存被映射到进程A、B各自的进程地址空间。进程A可以即时看到进程B对共享内存中数据的更新,反之亦然。由于多个进程共享同一块内存区域,必然需要某种同步机制,互斥锁和信号量都可以。
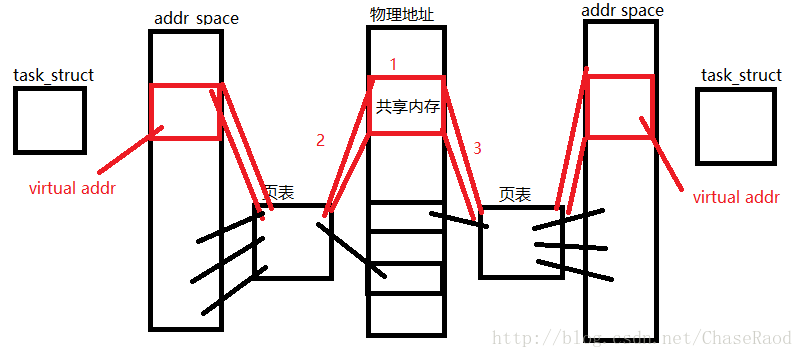
效率: 采用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝。对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次数据[1]: 一次从输入文件到共享内存区,另一次从共享内存区到输出文件。实际上,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时,再重新建 立共享内存区域。而是保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回 文件的。因此,采用共享内存的通信方式效率是非常高的。
共享内存实现机制
共享内存是通过把同一块内存分别映射到不同的进程空间中实现进程间通信。而共享内存本身不带任何互斥与同步机制,但当多个进程同时对同一内存进行读写操作时会破坏该内存的内容,所以,在实际中,同步与互斥机制需要用户来完成。
来看几个系统调用函数:
(1)创建共享内存
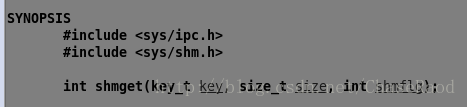
参数:key为输出型参数
size:size的大小应为1024整数倍(4k对齐)
shmflg:权限标志
(2)将共享内存映射到自己的内存空间:shmat
shmat是空间映射,通过创建的共享内存,在它能被进程访问之前,需要把该段内存映射到用户进程空间。shmaddr是用来指定共享内存映射到当前进程中的地址位置,要想改设置有用,shmflag必须设置为SHM_RND标志。大多情况下,应设置为空指针(void*)0,让系统自动选择地址,从而减小程序对硬件的依赖性。shmflag除了上面的设置外,还可以设置为SHM_RDONLY,使得映射过来的地址只读。
返回值:调用成功则返回映射地址的第一个字节,失败返回-1。
(3)解除映射:shmdt
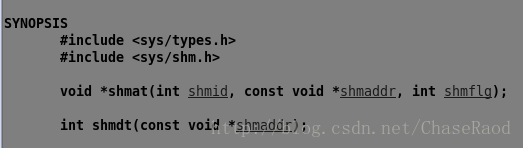
参数为要解除的地址空间。
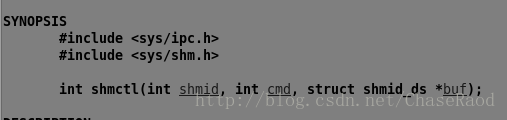


(4)控制共享内存
先来看第三个参数的结构体:
第二个参数cmd的选项:IPC_STAT:得到共享内存的状态,把共享内存的shmid_ds结构体复制到buf里
IPC_SET:改变共享内存的状态,把buf所指的结构体中的uid,gid,mode,复制到共享内存的shmid_ds结构体内
IPC_RMID:删除这块共享内存
BUF:共此内存管理结构体

代码实现:

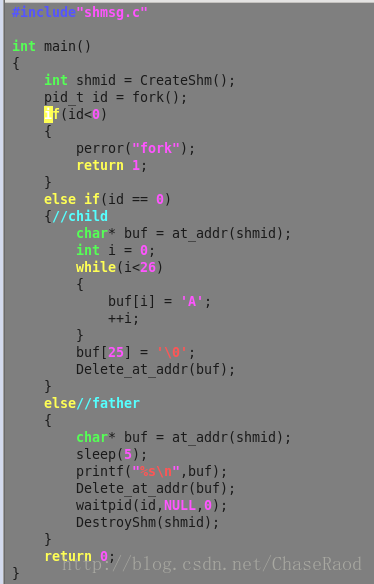
共享内存的特点:
(1)共享内存就是允许两个不想关的进程访问同一个内存
(2)共享内存是两个正在运行的进程之间共享和传递数据的最有效的方式
(3)不同进程之间共享的内存通常安排为同一段物理内存
(4)共享内存不提供任何互斥和同步机制,一般用信号量对临界资源进行保护。
(5)接口简单
所有进程间通信的特点:
(1)管道
管道分为命名管道和匿名管道。匿名管道只能单向通信,且只能在有亲缘关系的进程间使用,常用于父子进程,当一个进程创建了一个管道,并调用fork创建子进程后,父进程关闭读端,子进程关闭写端,实现单向通信。管道是面向字节流,自带互斥与同步机制,生命周期随进程。
命名管道与匿名管道:命名管道允许毫不相干的两个进程之间
(2)信号量
信号量是一个计数器,可以用来控制多个线程对共享资源的访问,它不是用于交换大批数据,而用于多线程之间的同步,常作为一种锁机制,防止某进程在访问资源时其他进程也来访问,因此,主要作为进程间以及同一进程的不同线程间的同步手段。
(3)消息队列
消息队列是消息的链表,存放在内核中并由消息队列标识符标识,消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区受限等特点。消息队列是UNIX下不同进程之间可以实现资源共享的 一种机制,UNIX允许不同进程将格式化的数据流以消息队列形式发送给任意进程,对消息队列具有操作权限的进程都可以使用msgget完成对消息队列的操作控制,通过使用消息类型,进程可以按顺序读信息,或为消息安排优先级顺序。
(4)共享内存
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问,共享内存是最快的IPC方式,它是针对其他IPC方式运行效率低而专门设计的,它往往与其他机制,如信号量,配合使用,来实现进程间的同步。
以上就是Linux共享内存实现机制的内容详细介绍,大家可以参考下,如果有疑问的可以到本站留言,进行讨论。感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
程序员也是半个运维了,在日常开发中经常会接触到Linux环境操作。小公司的开发人员甚至是兼了全运维的工作,下面整理了一些常用的Linux操作命令。
Linux常用指令
ls 显示文件或目录
-l 列出文件详细信息l(list)
-a 列出当前目录下所有文件及目录,包括隐藏的a(all)
mkdir 创建目录
-p 创建目录,若无父目录,则创建p(parent)
cd 切换目录
touch 创建空文件
vim / vi 创建/编辑文件
insert 编辑
:q 退出
:q! 强制退出
:wq 保存并退出
esc 退出编辑
echo 创建带有内容的文件
cat 查看文件内容
tar 打包压缩
-c 建立压缩档案
-x 解压缩文件
-z gzip压缩文件
-j bzip2压缩文件
-v 显示所有过程
-f 使用档名
cp 拷贝
-r 递归拷贝目录
mv 移动或重命名
rm 删除文件
-r 递归删除,可删除子目录及文件
-f 强制删除
chmod 变更文件或目录的权限
kill 杀进程
find 在文件系统中搜索某文件
wc 统计文本中行数、字数、字符数
grep 在文本文件中查找某个字符串
rmdir 删除空目录
tree 树形结构显示目录,需要安装tree包
pwd 显示当前目录
ln 创建链接文件
date 显示系统时间
more / less 分页显示文本文件内容
head / tail 显示文件头、尾内容
sudo 用来以其他身份来执行命令,预设的身份为root
su 换当前用户身份到其他用户身份
stat 显示指定文件的详细信息,比ls更详细
who 显示在线登陆用户
whoami 显示当前操作用户
hostname 显示主机名
uname 显示系统信息
top 动态显示当前耗费资源最多进程信息
ps 显示瞬间进程状态
-e 显示所有进程
-f 全格式
du 查看目录大小
-s 只显示目录大小的总合
-h 带单位显示目录大小
df 查看磁盘大小df
-h 带有单位显示磁盘信息
free 查看内存情况
-b 单位(bytes)
-k 单位(KB)
-m 单位(MB)
-g 单位(GB)
ifconfig 查看网络情况
ping 测试网络连通
netstat 显示网络状态信息
-ano 查看某个端口是否被占用
-tlnp 根据端口查找PID
man 查看Linux中的指令帮助
kill 杀进程不常用地命令
clear 清屏
reboot 重启系统
shutdown
-r 关机重启
-h 关机不重启
now 立刻关机由于我们自己使用的电脑未必有外网ip,因此我们需要一个有固定外网ip的服务器(随便搞个腾讯云,阿里云的小机子就行),然后用这台服务器与内网的机子进行通信,我们到时候要先登陆自己的服务器,然后再利用这个服务器去访问内网的主机。
1、准备好有固定ip的服务器A,以及待访问的内网机器B。两者都开着sshd服务,端口号默认都是22。顺便做好ssh免密码登陆。
2、内网主机B主动连接服务器A,执行以下命令:
>$ ssh -NfR 10000:localhost:22 username@servername -p 22
这条命令的意思是在后台执行(-f),不实际连接而是做port forwarding(-N),做反向ssh(-R),将远程服务器的10000端口映射成连接本机(B)与该服务器的反向ssh的端口。
附:这里有必要加强一下记忆,这个端口号一不小心就容易搞混
man文档中的参数命令是这样的:
-R [bind_address:]port:host:hostport
-R [bind_address:]port:local_socket
-R remote_socket:host:hostport
-R remote_socket:local_socket
bind_address以及其后面的port是指远程主机的ip以及端口,host以及其后的hostport是指本机的ip和端口。由于ssh命令本身需要远程主机的ip(上上条命令中的servername),因此这个bind_address原则上是可以省略的。
执行完这条命令,我们可以在服务器A上看到他的10000端口已经开始监听:
~]$ ss -ant | grep 10000
LISTEN 0 128 127.0.0.1:10000 *:*
3、在上面的操作中,这个1111端口就已经映射成了内网主机B的22端口了,现在我们只要ssh到自己的这个端口就行了。在服务器A中执行:
>$ ssh username@localhost -p 10000
这样就成功的登陆了内网的主机了。
功能优化
上面的做法其实有一个问题,就是反向ssh可能会不稳定,主机B对服务器A的端口映射可能会断掉,那么这时候就需要主机B重新链接,而显然远在外地的我无法登陆B
这其实有一个非常简单的解决方案,就是用autossh替代步骤2中的ssh:
C:\ > autossh -M 2222 -NfR 10000:localhost:22 username@servername -p 22
后面的参数跟ssh都一样,只是多了一个-M参数,这个参数的意思就是用本机的2222端口来监听ssh,每当他断了就重新把他连起来。。。不过man文档中也说了,这个端口又叫echo port,他其实是有一对端口的形式出现,第二个端口就是这个端口号加一。因此我们要保证这个端口号和这个端口号加一的端口号不被占用。
有时,我们会想在局域网外访问局域网内的机器。这时,我们可以使用SSH的反向连接来实现。
设备A:位于局域网内,可以访问代理服务器B。 假设该设备IP:A.A.A.A,用户名userA
设备B:位于局域网外,作为访问设备A的代理服务器,不可访问A。假设该设备IP:B.B.B.B,用户名userB
设备C:想要访问A的设备,可以访问B,无法直接访问A。假设该设备IP:C.C.C.C,用户名userC
目标:设备C可以通过SSH访问局域网内设备C
条件:三台设备都需要包含SSH客户端,A,B设备需要包含SSH服务端。
在A设备上建立A设备到B设备的反向代理:
ssh -fCNR <port_b1>:localhost:22 userB@B.B.B.B
例如:ssh -fCNR 10000:localhost:22 userB@B.B.B.B (此时B设备上已经可以通过ssh -p 10000 userA@localhost连接到设备A)
<port_b1>:建立在B机器上,用来代理设备A机器22端口的端口。
userB@B.B.B.B :B机器的用户名和IP地址。
在B设备上建立B设备到A设备的正向代理:(这样做的目的是为了实现和外网的通信)
ssh -fCNL *:<port_b2>:localhost:<port_b1> userB@localhost
例如:ssh -fCNL *:10001:localhost:10000 userB@localhost
<port_b2>:用作本地转发的端口,用来和外网通信,并将数据转发到<port_b1>,实现从其他机器可以访问。
*代表可以接受来自任意机器的访问。
现在C机器上可以通过B机器SSH到A机器
ssh -p<port_b2> userA@B.B.B.B
参数介绍
-f 后台运行-C 允许压缩数据-N 不执行任何命令-R 将端口绑定到远程服务器,反向代理-L 将端口绑定到本地客户端,正向代理
转自:https://my.oschina.net/macwe/blog/1531024
本文解读一下从CPU加电自检到启动init进程的过程, 先通过下面这张图大致看一下Linux启动的整个过程。
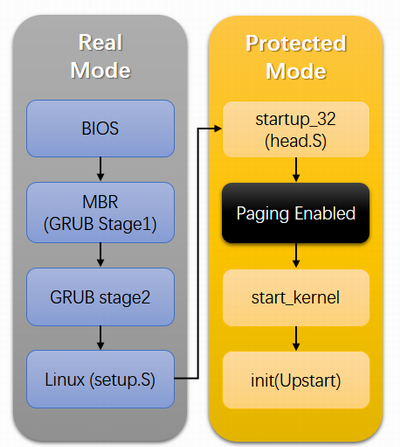
本文的分析环境是GRUB 0.97 + Linux 2.6.18。
CPU加电后首先工作在实模式并初始化CS:IP=FFFF:FFF0,BIOS的入口代码必须从该地址开始。BIOS完成相应的硬件检查并提供一系列中断服务例程,这些中断服务提供给系统软件访问硬件资源(比如磁盘、显示器等),最后选择一个启动盘加载第一个扇区(即:MBR,共512字节)数据到内存0x7C00处,并从这里开始执行指令(CS:IP=0000:7C00),对于笔者的电脑来说这就是GRUB的Stage1部分。
GRUB的作用是bootloader,用来引导各种OS的。
Stage1就是MBR,由BIOS把它从磁盘的0扇区加载到0x7c00处,大小固定位512字节,此时的CPU上下文如下:
eax=0011aa55 ebx=00000080 ecx=00000000 edx=00000080 esi=0000f4a0 edi=0000fff0
eip=00007c00 esp=00007800 ebp=00000000 iopl=0 nv up ei pl zr na po nc
cs=0000 ds=0000 es=0000 fs=0000 gs=0000 ss=0000 eflags=00000246
// 注: dl=启动磁盘号, 00H~7FH是软盘, 80H~FFH是硬盘。
因为只能是512字节,大小受限,它就干一件事,把Stage2的第一个512字节读取到0x8000,然后jmp到0x8000继续执行。
磁盘扇区寻址有两种方式:
(2^10) * (2^8) * (2^6) * 512 = 8GB的硬盘容量,现在的硬盘明显不够用了。(2^48) * 512 = 128PB的硬盘空间。虽然机械上还是CHS的结构,不过磁盘的固件会自动完成LBA到CHS的转换。因为CHS明显不适合现在的硬盘,所以LBA模式寻址是现在的PC的标配了吧!万一磁盘不支持LBA或者是软盘,需要我们手工转换成CHS模式。转换公式如下(就是三维空间定位一个点的问题):
磁道号C = LBA / 每磁道的扇区数SPT / 盘面总HPC
磁头号H = (LBA / 每磁道的扇区数SPT) mod HPC
扇区号S = (LBA mod SPT) + 1
判断是否支持LBA模式
/* check if LBA is supported */
movb $0x41, %ah
movw $0x55aa, %bx
int $0x13
如果返回成功(CF=1)并且BX值是0xAA55表示支持LBA寻址(用Extensions方法)。
注意:3.5英寸软盘需要使用CHS方式寻址,它的CHS参数是80个柱面、2个磁头、每个磁道18个扇区,每扇区512字节,共1.44MB容量。
LBA模式读的功能号是AH=42h,DL参数是磁盘号,DS:SI参数是Disk Address Packet(DAP)结构体的内存地址,定义如下:
struct DAP {
uint8_t sz; // 结构体大小
uint8_t unused;
uint16_t sector_cnt; // 需要都的扇区总数
struct dst_addr { // 内存地址,读到这里
uint16_t offset;
uint16_t segment;
};
uint64_t lba_addr; // 磁盘的LBA地址
};
参考:
Stage2就是GRUB剩下的全部的代码了,包括BIOS中断服务的封装给C代码使用、键盘驱动、文件系统驱动、串口、网络驱动等等,它提供了一个小型的命令行环境,可以解析用户输入命令并执行对OS的启动。
首先Stage2的头512字节(start.S)被加载到0x8000,并在这里开始执行,此时的CPU上下文如下:
eax=00000000 ebx=00007000 ecx=00646165 edx=00000080 esi=00007c05 edi=0000fff0
eip=00008000 esp=00001ffe ebp=00000000 iopl=0 nv up ei pl zr na po nc
cs=0000 ds=0000 es=0800 fs=0000 gs=0000 ss=0000 eflags=00000246
start.S的工作是把Stage2的后续部分全部加载到内存中(从0x8200开始),有103KB大小。
asm.S是0x8200处的代码,先看一下CPU上下文环境:
eax=00000e00 ebx=00000001 ecx=00646165 edx=00000080 esi=00008116 edi=000081e8
eip=00008200 esp=00001ffe ebp=000062d8 iopl=0 nv up ei pl zr na po nc
cs=0000 ds=0000 es=1ae0 fs=0000 gs=0000 ss=0000 eflags=00000246
cli
/* set up %ds, %ss, and %es */
/* cs=0000 ds=0000 es=0000 fs=0000 gs=0000 ss=0000 */
xorw %ax, %ax
movw %ax, %ds
movw %ax, %ss
movw %ax, %es
/* set up the real mode/BIOS stack */
movl $STACKOFF, %ebp
movl %ebp, %esp
sti
此时:
cs=0000 ds=0000 es=0000 ss=0000 esp=00001ff0 ebp=00001ff0。
因为GRUB没有实现自己的中断服务,所以访问硬件资源还是使用BIOS的中断服务例程(实模式)。GRUB的命令行环境是工作在保护模式下的,所以当GRUB需要访问BIOS中断的时候需要切换回实模式,于是在GRUB执行过程中会有频繁的实模式和保护模式的互相切换操作,当切换回实模式后别忘了保存保护模式下的栈指针。
(1) 实模式进入保护模式
/* transition to protected mode */
DATA32 call EXT_C(real_to_prot)
/* The ".code32" directive takes GAS out of 16-bit mode. */
.code32
下图是实模式到保护模式的切换步骤:

GRUB没有设置分页机制和新的中断,所以GRUB的保护模式访问的是物理内存且是不能使用INT指令,不过对于bootloader来说够用了。因为需要切换到保护模式栈,原来的返回地址要放到新的栈上,以保证能够正常ret:
ENTRY(real_to_prot)
...
/* put the return address in a known safe location */
movl (%esp), %eax
movl %eax, STACKOFF ; 把返回地址保存起来备用
/* get protected mode stack */
movl protstack, %eax
movl %eax, %esp
movl %eax, %ebp ; 设置保护模式的栈
/* get return address onto the right stack */
movl STACKOFF, %eax
movl %eax, (%esp) ; 把返回地址重新放到栈上
/* zero %eax */
xorl %eax, %eax
/* return on the old (or initialized) stack! */
ret ; 正常返回
(2) 保护模式切换回实模式
/* enter real mode */
call EXT_C(prot_to_real)
.code16
下图说明了保护模式切换回实模式的步骤:

保护模式的栈需要保存起来以便恢复现场,让C代码正确运行,实模式的栈每次都重置为STACKOFF即可,和(1)一样,也要设置好返回地址:
ENTRY(prot_to_real)
...
/* save the protected mode stack */
movl %esp, %eax
movl %eax, protstack ; 把栈保存起来
/* get the return address */
movl (%esp), %eax
movl %eax, STACKOFF ; 返回地址放到实模式栈里
/* set up new stack */
movl $STACKOFF, %eax ; 设置实模式的栈
movl %eax, %esp
movl %eax, %ebp
...
C的运行环境主要包括栈、bss数据区、代码区。随着切换到保护模式,栈已经设置好了;随着Stage2从磁盘加载到内存,代码区和bss区都已经在内存了,最后还需要把bss区给初始化一下(清0),接下来即可愉快的执行C代码了。
先执行一个init_bios_info()获取BIOS的信息,比如被BIOS使用的内存空间(影响我们Linux映像加载的位置)、磁盘信息、ROM信息、APM信息,最后调用cmain()。 cmain()函数在stage2.c文件中,其中最主要的函数run_menu()是启动一个死循环来提供命令行解析执行环境。
如果grub.cfg或者用户执行kenrel命令,会调用load_image()函数来将内核加载到内存中。至于如何加载linux镜像在Documentation的boot.txt和zero-page.txt有详细说明。
load_image()是一个非常长的函数,它要处理支持的各种内核镜像格式。Linux镜像vmlinuz文件头是struct linux_kernel_header结构体,该结构体里头说明了这个镜像使用的boot协议版本、实模式大小、加载标记位和需要GRUB填写的一些参数(比如:内核启动参数地址)。
mbi.mem_lower * 1024(一般是0x90000)区域。我们正常的启动过程调用的是big_linux_boot()函数,把实模式部分copy到0x90000后,设置其他段寄存器值位0x9000, 设置CS:IP=9020:0000开始执行(使用far jmp)。
至此GRUB的工作完成,接下来执行权交给Linux了。
该文件在arch/i386/boot/setup.S,主要作用是收集硬件信息并进入保护模式head.S。初始的CPU上下文如下:
eax=00000000 ebx=00009000 ecx=00000000 edx=00000003 esi=002d8b54 edi=0009a000
eip=00000000 esp=00009000 ebp=00001ff0 iopl=0 nv up di pl zr na po nc
cs=9020 ds=9000 es=9000 fs=9000 gs=9000 ss=9000 eflags=00000046
先检查自己setup.S是否合法,主要是检查末尾的两个magic是否一致
# Setup signature -- must be last
setup_sig1: .word SIG1
setup_sig2: .word SIG2
主要是通过BIOS中断来收集硬件信息。收集的信息包括内存大小、键盘、鼠标、显卡、硬盘、APM等等。收集的硬件信息保存在0x9000处:
# 设置ds = 0x9000,用来保存硬件信息
movw %cs, %ax # aka SETUPSEG
subw $DELTA_INITSEG, %ax # aka INITSEG
movw %ax, %ds
这里看一下如何获取内存大小,这样OS才能进行内存管理。这里用三种方法获取内存信息:
struct address_range_descriptor {
uint32_t base_addr_low; // 起始物理地址
uint32_t base_addr_high;
uint32_t length_low; // 长度
uint32_t length_high;
uint8_t type; // 1=OS可用的, 2=保留的,OS不可用
};
扩展阅读:http://wiki.osdev.org/Detecting_Memory_(x86)#E820h
让CPU访问1MB以上的扩展内存,否则访问的是X mod 1MB的地址。下面列举三种开启A20的方法:
inb $0x92, %al # Configuration Port A
orb $0x02, %al # "fast A20" version
andb $0xFE, %al # don't accidentally reset
outb %al, $0x92
movw $0x2401, %ax
pushfl # Be paranoid about flags
int $0x15
popfl
movb $0xD1, %al # command write
outb %al, $0x64
call empty_8042
movb $0xDF, %al # A20 on
outb %al, $0x60
call empty_8042
这里的IDT全部是0;Linux目前使用的GDT如下:
gdt:
.fill GDT_ENTRY_BOOT_CS,8,0
.word 0xFFFF # 4Gb - (0x100000*0x1000 = 4Gb)
.word 0 # base address = 0
.word 0x9A00 # code read/exec
.word 0x00CF # granularity = 4096, 386
# (+5th nibble of limit)
.word 0xFFFF # 4Gb - (0x100000*0x1000 = 4Gb)
.word 0 # base address = 0
.word 0x9200 # data read/write
.word 0x00CF # granularity = 4096, 386
# (+5th nibble of limit)
gdt_end:
这里只定义了两个DPL为0的代码段和数据段,只给内核使用的。
这里使用lmsw指令,它和mov cr0, X是等价的
movw $1, %ax # protected mode (PE) bit
lmsw %ax # This is it!
jmp flush_instr
至此硬件信息就收集完成,这些收集到的硬件信息都保存在0x90000处,后续OS可以使用这些硬件信息来管理了。
该文件位于arch/i386/kernel/head.S,这个是内核保护模式的代码的起点,笔者电脑的位置在0x100000,此时CPU上下文是:
eax=00000001 ebx=00000000 ecx=0000ff03 edx=47530081 esi=00090000 edi=00090000
eip=00100000 esp=00008ffe ebp=00001ff0 iopl=0 nv up di pl nz na pe nc
cs=0010 ds=0018 es=0018 fs=0018 gs=0018 ss=0018 eflags=00000002
注:已经进入保护模式,CS的值是GDT表项的索引。
它的作用就是设置真正的分段机制和分页机制、启动多处理器、设置C运行环境,最后执行start_kernel()函数。
boot_gdt_table就是临时的GDT,其实和start.S的一样:
lgdt boot_gdt_descr - __PAGE_OFFSET
movl $(__BOOT_DS),%eax
movl %eax,%ds
movl %eax,%es
movl %eax,%fs
movl %eax,%gs
ENTRY(boot_gdt_table)
.fill GDT_ENTRY_BOOT_CS,8,0
.quad 0x00cf9a000000ffff /* kernel 4GB code at 0x00000000 */
.quad 0x00cf92000000ffff /* kernel 4GB data at 0x00000000 */
为了让C代码正常运行,bss区全部清0,启动参数需要移动到boot_params位置。
临时的页表,只要能够满足内核使用就行。页目录表是swapper_pg_dir,它是一个4096大小的内存区域,默认全是0。一般__PAGE_OFFSET=0xC0000000(3GB),这是要把物理地址0x00000000映射到0xc0000000的地址空间(内核地址空间)。下面是页目录表和页表的初始化代码:
page_pde_offset = (__PAGE_OFFSET >> 20); // 3072,页目录的偏移
// 页目录表存放在pg0位置,arch/i386/kernel/vmlinux.lds中定义
movl $(pg0 - __PAGE_OFFSET), %edi
movl $(swapper_pg_dir - __PAGE_OFFSET), %edx // edx是页目录表的地址
movl $0x007, %eax /* 0x007 = PRESENT+RW+USER */
10:
// 创建一个页目录项
leal 0x007(%edi),%ecx /* Create PDE entry */
movl %ecx,(%edx) /* Store identity PDE entry */
movl %ecx,page_pde_offset(%edx) /* Store kernel PDE entry */
addl $4,%edx // 指向swapper_pg_dir的下一个项
movl $1024, %ecx // 每个页表1024个项目
11:
stosl // eax -> [edi]; edi = edi + 4
addl $0x1000,%eax // 每次循环,下一个页目录项
loop 11b
/* End condition: we must map up to and including INIT_MAP_BEYOND_END */
/* bytes beyond the end of our own page tables; the +0x007 is the attribute bits */
leal (INIT_MAP_BEYOND_END+0x007)(%edi),%ebp // 页表覆盖到这里就终止
cmpl %ebp,%eax
jb 10b
movl %edi,(init_pg_tables_end - __PAGE_OFFSET)
下面是对上面代码的翻译(这样更有利于理解):
extern uint32_t *pg0; // 初始值全0
extern uint32_t *swapper_pg_dir; // 初始值全0
void init_page_tables()
{
uint32_t PAGE_FLAGS = 0x007; // PRESENT+RW+USER
uint32_t page_pde_offset = (_PAGE_OFFSET >> 20); // 3072
uint32_t addr = 0 | PAGE_FLAGS; // 内存地址+页表属性
uint32_t *pg_dir_ptr = swapper_pg_dir; // 页目录表项指针
uint32_t *pg0_ptr = pg0; // 页表项指针
for (;;) {
// 设置页目录项,同时映射两个地址,让物理地址和虚拟地址都能访问,
*pg_dir_ptr = pg0 | PAGE_FLAGS; // 0, 1
*(uint32_t *)((char *)pg_dir_ptr + page_pde_offset) = pg0 | PAGE_FLAGS; // 768, 769
pg_dir_ptr++;
// 设置页表项目
for (int i = 0; i < 1024; i++) {
*pg0++ = addr;
addr += 0x1000;
}
// 退出条件,实际上只映射了两个页目录就退出了(0,1,768, 769)
if (pg0[INIT_MAP_BEYOND_END] | PAGE_FLAGS) >= addr) {
init_pg_tables_end = pg0_ptr;
return;
}
}
};
/* Set up the stack pointer */
lss stack_start,%esp
ENTRY(stack_start)
.long init_thread_union+THREAD_SIZE
.long __BOOT_DS
/* arch/i386/kernel/init_task.c
* Initial thread structure.
*
* We need to make sure that this is THREAD_SIZE aligned due to the
* way process stacks are handled. This is done by having a special
* "init_task" linker map entry..
*/
union thread_union init_thread_union
__attribute__((__section__(".data.init_task"))) =
{ INIT_THREAD_INFO(init_task) };
内核最初使用的栈是init_task进程的,也就是0号进程的栈,这个进程是系统唯一一个静态定义而不是通过fork()产生的进程。
lgdt cpu_gdt_descr // 真正的GDT
lidt idt_descr //真正的IDT
ljmp $(__KERNEL_CS),$1f // 重置CS
1: movl $(__KERNEL_DS),%eax # reload all the segment registers
movl %eax,%ss # after changing gdt. // 重置SS
movl $(__USER_DS),%eax # DS/ES contains default USER segment
movl %eax,%ds
movl %eax,%es
xorl %eax,%eax # Clear FS/GS and LDT
movl %eax,%fs
movl %eax,%gs
lldt %ax
cld # gcc2 wants the direction flag cleared at all times
// push一个假的返回地址以满足 start_kernel()函数return的要求
pushl %eax # fake return address
对于IDT先全部初始化成ignore_int例程:
setup_idt:
lea ignore_int,%edx
movl $(__KERNEL_CS << 16),%eax
movw %dx,%ax /* selector = 0x0010 = cs */
movw $0x8E00,%dx /* interrupt gate - dpl=0, present */
lea idt_table,%edi
mov $256,%ecx
rp_sidt:
movl %eax,(%edi)
movl %edx,4(%edi)
addl $8,%edi
dec %ecx
jne rp_sidt
ret
ignore_int例程就干一件事,打印一个错误信息"Unknown interrupt or fault at EIP %p %p %p\n"。
对于GDT我们最关心的__KERNEL_CS、__KERNEL_DS、__USER_CS、__USER_DS这4个段描述符:
.quad 0x00cf9a000000ffff /* 0x60 kernel 4GB code at 0x00000000 */
.quad 0x00cf92000000ffff /* 0x68 kernel 4GB data at 0x00000000 */
.quad 0x00cffa000000ffff /* 0x73 user 4GB code at 0x00000000 */
.quad 0x00cff2000000ffff /* 0x7b user 4GB data at 0x00000000 */
至此分段机制、分页机制、栈都设置好了,接下去可以开心的jmp start_kernel了。
该函数在linux/init/main.c文件里。我们可以认为start_kernel是0号进程init_task的入口函数,0号进程代表整个linux内核且每个CPU有一个。 这个函数开始做一系列的内核功能初始化,我们重点看rest_init()函数。
这是start_kernel的最后一行,它启动一个内核线程运行init函数后就什么事情也不做了(死循环,始终交出CPU使用权)。
static void noinline rest_init(void)
{
kernel_thread(init, NULL, CLONE_FS | CLONE_SIGHAND); // 启动init
……
/* Call into cpu_idle with preempt disabled */
cpu_idle(); // 0号进程什么事也不做
}
该函数的末尾fork了”/bin/init”进程。这样1号进程init就启动了,接下去就交给init进程去做应用层该做的事情了!
// 以下进程启动后父进程都是0号进程
if (ramdisk_execute_command) {
run_init_process(ramdisk_execute_command);
printk(KERN_WARNING "Failed to execute %s\n",
ramdisk_execute_command);
}
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead of init if we are
* trying to recover a really broken machine.
*/
if (execute_command) {
run_init_process(execute_command);
printk(KERN_WARNING "Failed to execute %s. Attempting "
"defaults...\n", execute_command);
}
run_init_process("/sbin/init");
run_init_process("/etc/init");
run_init_process("/bin/init");
run_init_process("/bin/sh");
以上解读的内容只在0号CPU上执行,如果是多CPU的环境,还要初始化其他的CPU。多CPU启动的起点是start_kernel()->rest_init()–>init()->smp_init()。而smp_init()函数给每个CPU上调用cpu_up()和do_boot_cpu()函数,每个CPU都要再走一遍head.S的流程,然后启动自己的idle进程(内核态0号进程)。
i386和x64的启动代码主要区别在head.S中。
__USER32_CS、__USER32_DS和__KERNEL32_CS。FS:XX = MSR_FS_BASE + XX, GS:XX = MSR_GS_BASE + XX, 不是段描述符索引了(像实模式的分段)。信号是Linux编程中非常重要的部分,本文将详细介绍信号机制的基本概念、Linux对信号机制的大致实现方法、如何使用信号,以及有关信号的几个系统调用。
信号机制是进程之间相互传递消息的一种方法,信号全称为软中断信号,也有人称作软中断。从它的命名可以看出,它的实质和使用很象中断。所以,信号可以说是进程控制的一部分。
软中断信号(signal,又简称为信号)用来通知进程发生了异步事件。进程之间可以互相通过系统调用kill发送软中断信号。内核也可以因为内部事件而给进程发送信号,通知进程发生了某个事件。注意,信号只是用来通知某进程发生了什么事件,并不给该进程传递任何数据。
收 到信号的进程对各种信号有不同的处理方法。
处理方法可以分为三类:
在进程表的表项中有一个软中断信号域,该域中每一位对应一个信号,当有信号发送给进程时,对应位置位。由此可以看出,进程对不同的信号可以同时保留,但对于同一个信号,进程并不知道在处理之前来过多少个。
发出信号的原因很多,这里按发出信号的原因简单分类,以了解各种信号:
Linux支持的信号列表如下。很多信号是与机器的体系结构相关的
POSIX.1中列出的信号:
信号 值 处理动作 发出信号的原因
———————————————————————-
SIGHUP 1 A 终端挂起或者控制进程终止
SIGINT 2 A 键盘中断(如break键被按下)
SIGQUIT 3 C 键盘的退出键被按下
SIGILL 4 C 非法指令
SIGABRT 6 C 由abort(3)发出的退出指令
SIGFPE 8 C 浮点异常
SIGKILL 9 AEF Kill信号
SIGSEGV 11 C 无效的内存引用
SIGPIPE 13 A 管道破裂: 写一个没有读端口的管道
SIGALRM 14 A 由alarm(2)发出的信号
SIGTERM 15 A 终止信号
SIGUSR1 30,10,16 A 用户自定义信号1
SIGUSR2 31,12,17 A 用户自定义信号2
SIGCHLD 20,17,18 B 子进程结束信号
SIGCONT 19,18,25 进程继续(曾被停止的进程)
SIGSTOP 17,19,23 DEF 终止进程
SIGTSTP 18,20,24 D 控制终端(tty)上按下停止键
SIGTTIN 21,21,26 D 后台进程企图从控制终端读
SIGTTOU 22,22,27 D 后台进程企图从控制终端写
下面的信号没在POSIX.1中列出,而在SUSv2列出
信号 值 处理动作 发出信号的原因
——————————————————————–
SIGBUS 10,7,10 C 总线错误(错误的内存访问)
SIGPOLL A Sys V定义的Pollable事件,与SIGIO同义
SIGPROF 27,27,29 A Profiling定时器到
SIGSYS 12,-,12 C 无效的系统调用 (SVID)
SIGTRAP 5 C 跟踪/断点捕获
SIGURG 16,23,21 B Socket出现紧急条件(4.2 BSD)
SIGVTALRM 26,26,28 A 实际时间报警时钟信号(4.2 BSD)
SIGXCPU 24,24,30 C 超出设定的CPU时间限制(4.2 BSD)
SIGXFSZ 25,25,31 C 超出设定的文件大小限制(4.2 BSD)
(对于SIGSYS,SIGXCPU,SIGXFSZ,以及某些机器体系结构下的SIGBUS,Linux缺省的动作是A (terminate),SUSv2 是C (terminate and dump core))。
下面是其它的一些信号
信号 值 处理动作 发出信号的原因
———————————————————————-
SIGIOT 6 C IO捕获指令,与SIGABRT同义
SIGEMT 7,-,7
SIGSTKFLT -,16,- A 协处理器堆栈错误
SIGIO 23,29,22 A 某I/O操作现在可以进行了(4.2 BSD)
SIGCLD -,-,18 A 与SIGCHLD同义
SIGPWR 29,30,19 A 电源故障(System V)
SIGINFO 29,-,- A 与SIGPWR同义
SIGLOST -,-,- A 文件锁丢失
SIGWINCH 28,28,20 B 窗口大小改变(4.3 BSD, Sun)
SIGUNUSED -,31,- A 未使用的信号(will be SIGSYS)
(在这里,- 表示信号没有实现;有三个值给出的含义为,第一个值通常在Alpha和Sparc上有效,中间的值对应i386和ppc以及sh,最后一个值对应mips。信号29在Alpha上为SIGINFO / SIGPWR ,在Sparc上为SIGLOST。)
处理动作一项中的字母含义如下
A 缺省的动作是终止进程
B 缺省的动作是忽略此信号
C 缺省的动作是终止进程并进行内核映像转储(dump core)
D 缺省的动作是停止进程
E 信号不能被捕获
F 信号不能被忽略
上 面介绍的信号是常见系统所支持的。以表格的形式介绍了各种信号的名称、作用及其在默认情况下的处理动作。各种默认处理动作的含义是:终止程序是指进程退 出;忽略该信号是将该信号丢弃,不做处理;停止程序是指程序挂起,进入停止状况以后还能重新进行下去,一般是在调试的过程中(例如ptrace系统调 用);内核映像转储是指将进程数据在内存的映像和进程在内核结构中存储的部分内容以一定格式转储到文件系统,并且进程退出执行,这样做的好处是为程序员提 供了方便,使得他们可以得到进程当时执行时的数据值,允许他们确定转储的原因,并且可以调试他们的程序。
注意 信号SIGKILL和SIGSTOP既不能被捕捉,也不能被忽略。信号SIGIOT与SIGABRT是一个信号。可以看出,同一个信号在不同的系统中值可能不一样,所以建议最好使用为信号定义的名字,而不要直接使用信号的值。
只有第9种信号(SIGKILL)才可以无条件终止进程,其他信号进程都有权利忽略,
下面是常用的信号:
HUP 1 终端断线
INT 2 中断(同 Ctrl + C)
QUIT 3 退出(同 Ctrl + \)
TERM 15 终止
KILL 9 强制终止
CONT 18 继续(与STOP相反, fg/bg命令)
STOP 19 暂停(同 Ctrl + Z)
linux中存在一些按键,那么如何查阅目前的一些按键内容了?可以利用stty(setting tty 终端机的意思)。stty也可以帮助设置终端机的输入按键代表意义。
>$ stty -a
speed 38400 baud; rows 24; columns 80; line = 0;
intr = ^C; quit = ^\; erase = ^?; kill = ^U; eof = ^D; eol = ;
eol2 = ; swtch = ; start = ^Q; stop = ^S; susp = ^Z; rprnt = ^R;
werase = ^W; lnext = ^V; flush = ^O; min = 1; time = 0;
-parenb -parodd cs8 -hupcl -cstopb cread -clocal -crtscts
-ignbrk -brkint -ignpar -parmrk -inpck -istrip -inlcr -igncr icrnl ixon -ixoff
-iuclc -ixany -imaxbel -iutf8
opost -olcuc -ocrnl onlcr -onocr -onlret -ofill -ofdel nl0 cr0 tab0 bs0 vt0 ff0
isig icanon iexten echo echoe echok -echonl -noflsh -xcase -tostop -echoprt
echoctl echoke
需要注意的是特殊字体那几个,此外^表示[Ctrl]那个按键的意思,如:intr = ^C表示利用【Ctrl】+c来完成的。几个重要的代表意义是:
eof:End of file的意思,代表结束输入;
erase:向前删除一个字符;
intr:送出一个interrupt(中断)的信号给目前正在运行的程序;
kill:删除在目前命令行上的所有字符;
quit:送出一个quit的信号给目前正在运行的进程;
start:在某个进程停止后,重新启动它的输出;
stop:停止目前屏幕的输出;
susp:送出一个terminal stop的信号给正在运行的进程;
如果你想要执行[ctrl]+h来进行字符的删除,那么可以执行:
root@mycomputer:~# stty erase ^h
Ctrl+C终止目前的命令
Ctrl+D输入结束(eof),例如邮件结束的时候
eof代表End of file的意思,代表结束输入
Ctrl+M就是Enter
Ctrl+S暂停屏幕的输出
Ctrl+Q恢复屏幕的输出
Ctrl+U在提示符下,将整行命令删除
Ctrl+Z暂停目前的命令
Ctrl+Z和Ctrl+C都是中断命令,但是它们的作用却不一样。
Ctrl+C是强制中断程序的执行,而Ctrl+Z是将任务中断,但是此任务并没有结束,还是在进程中只是保持挂起的状态,用户可以使用fg/bg操作继续前台或后台飞任务,fg命令重新启动前台被中断的任务。bg命令把被中断的任务放在后台执行。
来源:http://blog.sina.com.cn/s/blog_14ecbe4520102wrmv.html
信号具有平台相关性,不同平台下能使用的信号种类是有差异的。
Linux下支持的信号:
SEGV, ILL, FPE, BUS, SYS, CPU, FSZ, ABRT, INT, TERM, HUP, USR1, USR2, QUIT, BREAK, TRAP, PIPE
Windows下支持的信号:
SEGV, ILL, FPE, ABRT, INT, TERM, BREAK
参考:http://colobu.com/2014/09/18/linux-tcpip-tuning/
有些性能瓶颈和Linux的TCP/IP的协议栈的设置有关,所以特别google了一下Linux TCP/IP的协议栈的参数意义和配置,记录一下。
如果想永久的保存参数的设置, 可以将参数加入到/etc/sysctl.conf中。如果想临时的更改参数的配置, 可以修改/proc/sys/net/ipv4/下的参数, 机器重启后更改失效。
linux内核参数优化
http://blog.chinaunix.net/uid-29081804-id-3830203.html
Sysctl命令及linux内核参数调整,系统工具的使用不熟悉地请先阅读上面的文章
linux内核参数注释
根据参数文件所处目录不同而进行分表整理
下列文件所在目录:/proc/sys/net/ipv4/
| 名称 | 默认值 | 建议值 | 描述 |
| tcp_syn_retries | 5 | 1 | 对于一个新建连接,内核要发送多少个 SYN 连接请求才决定放弃。不应该大于255,默认值是5,对应于180秒左右时间。。(对于大负载而物理通信良好的网络而言,这个值偏高,可修改为2.这个值仅仅是针对对外的连接,对进来的连接,是由tcp_retries1决定的) |
| tcp_synack_retries | 5 | 1 | 对于远端的连接请求SYN,内核会发送SYN + ACK数据报,以确认收到上一个 SYN连接请求包。这是所谓的三次握手( threeway handshake)机制的第二个步骤。这里决定内核在放弃连接之前所送出的 SYN+ACK 数目。不应该大于255,默认值是5,对应于180秒左右时间。 |
| tcp_keepalive_time | 7200 | 600 | TCP发送keepalive探测消息的间隔时间(秒),用于确认TCP连接是否有效。
防止两边建立连接但不发送数据的攻击。 |
| tcp_keepalive_probes | 9 | 3 | TCP发送keepalive探测消息的间隔时间(秒),用于确认TCP连接是否有效。 |
| tcp_keepalive_intvl | 75 | 15 | 探测消息未获得响应时,重发该消息的间隔时间(秒)。默认值为75秒。 (对于普通应用来说,这个值有一些偏大,可以根据需要改小.特别是web类服务器需要改小该值,15是个比较合适的值) |
| tcp_retries1 | 3 | 3 | 放弃回应一个TCP连接请求前﹐需要进行多少次重试。RFC 规定最低的数值是3 |
| tcp_retries2 | 15 | 5 | 在丢弃激活(已建立通讯状况)的TCP连接之前﹐需要进行多少次重试。默认值为15,根据RTO的值来决定,相当于13-30分钟(RFC1122规定,必须大于100秒).(这个值根据目前的网络设置,可以适当地改小,我的网络内修改为了5) |
| tcp_orphan_retries | 7 | 3 | 在近端丢弃TCP连接之前﹐要进行多少次重试。默认值是7个﹐相当于 50秒 – 16分钟﹐视 RTO 而定。如果您的系统是负载很大的web服务器﹐那么也许需要降低该值﹐这类 sockets 可能会耗费大量的资源。另外参的考tcp_max_orphans。(事实上做NAT的时候,降低该值也是好处显著的,我本人的网络环境中降低该值为3) |
| tcp_fin_timeout | 60 | 2 | 对于本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间。对方可能会断开连接或一直不结束连接或不可预料的进程死亡。默认值为 60 秒。 |
| tcp_max_tw_buckets | 180000 | 36000 | 系统在同时所处理的最大 timewait sockets 数目。如果超过此数的话﹐time-wait socket 会被立即砍除并且显示警告信息。之所以要设定这个限制﹐纯粹为了抵御那些简单的 DoS 攻击﹐不过﹐如果网络条件需要比默认值更多﹐则可以提高它(或许还要增加内存)。(事实上做NAT的时候最好可以适当地增加该值) |
| tcp_tw_recycle | 0 | 1 | 打开快速 TIME-WAIT sockets 回收。除非得到技术专家的建议或要求﹐请不要随意修改这个值。(做NAT的时候,建议打开它) |
| tcp_tw_reuse | 0 | 1 | 表示是否允许重新应用处于TIME-WAIT状态的socket用于新的TCP连接(这个对快速重启动某些服务,而启动后提示端口已经被使用的情形非常有帮助) |
| tcp_max_orphans | 8192 | 32768 | 系统所能处理不属于任何进程的TCP sockets最大数量。假如超过这个数量﹐那么不属于任何进程的连接会被立即reset,并同时显示警告信息。之所以要设定这个限制﹐纯粹为了抵御那些简单的 DoS 攻击﹐千万不要依赖这个或是人为的降低这个限制。如果内存大更应该增加这个值。(这个值Redhat AS版本中设置为32768,但是很多防火墙修改的时候,建议该值修改为2000) |
| tcp_abort_on_overflow | 0 | 0 | 当守护进程太忙而不能接受新的连接,就象对方发送reset消息,默认值是false。这意味着当溢出的原因是因为一个偶然的猝发,那么连接将恢复状态。只有在你确信守护进程真的不能完成连接请求时才打开该选项,该选项会影响客户的使用。(对待已经满载的sendmail,apache这类服务的时候,这个可以很快让客户端终止连接,可以给予服务程序处理已有连接的缓冲机会,所以很多防火墙上推荐打开它) |
| tcp_syncookies | 0 | 1 | 只有在内核编译时选择了CONFIG_SYNCOOKIES时才会发生作用。当出现syn等候队列出现溢出时象对方发送syncookies。目的是为了防止syn flood攻击。 |
| tcp_stdurg | 0 | 0 | 使用 TCP urg pointer 字段中的主机请求解释功能。大部份的主机都使用老旧的 BSD解释,因此如果您在 Linux 打开它﹐或会导致不能和它们正确沟通。 |
| tcp_max_syn_backlog | 1024 | 16384 | 对于那些依然还未获得客户端确认的连接请求﹐需要保存在队列中最大数目。对于超过 128Mb 内存的系统﹐默认值是 1024 ﹐低于 128Mb 的则为 128。如果服务器经常出现过载﹐可以尝试增加这个数字。警告﹗假如您将此值设为大于 1024﹐最好修改include/net/tcp.h里面的TCP_SYNQ_HSIZE﹐以保持TCP_SYNQ_HSIZE16(SYN Flood攻击利用TCP协议散布握手的缺陷,伪造虚假源IP地址发送大量TCP-SYN半打开连接到目标系统,最终导致目标系统Socket队列资源耗尽而无法接受新的连接。为了应付这种攻击,现代Unix系统中普遍采用多连接队列处理的方式来缓冲(而不是解决)这种攻击,是用一个基本队列处理正常的完全连接应用(Connect()和Accept() ),是用另一个队列单独存放半打开连接。这种双队列处理方式和其他一些系统内核措施(例如Syn-Cookies/Caches)联合应用时,能够比较有效的缓解小规模的SYN Flood攻击(事实证明) |
| tcp_window_scaling | 1 | 1 | 该文件表示设置tcp/ip会话的滑动窗口大小是否可变。参数值为布尔值,为1时表示可变,为0时表示不可变。tcp/ip通常使用的窗口最大可达到 65535 字节,对于高速网络,该值可能太小,这时候如果启用了该功能,可以使tcp/ip滑动窗口大小增大数个数量级,从而提高数据传输的能力(RFC 1323)。(对普通地百M网络而言,关闭会降低开销,所以如果不是高速网络,可以考虑设置为0) |
| tcp_timestamps | 1 | 1 | Timestamps 用在其它一些东西中﹐可以防范那些伪造的 sequence 号码。一条1G的宽带线路或许会重遇到带 out-of-line数值的旧sequence 号码(假如它是由于上次产生的)。Timestamp 会让它知道这是个 ‘旧封包’。(该文件表示是否启用以一种比超时重发更精确的方法(RFC 1323)来启用对 RTT 的计算;为了实现更好的性能应该启用这个选项。) |
| tcp_sack | 1 | 1 | 使用 Selective ACK﹐它可以用来查找特定的遗失的数据报— 因此有助于快速恢复状态。该文件表示是否启用有选择的应答(Selective Acknowledgment),这可以通过有选择地应答乱序接收到的报文来提高性能(这样可以让发送者只发送丢失的报文段)。(对于广域网通信来说这个选项应该启用,但是这会增加对 CPU 的占用。) |
| tcp_fack | 1 | 1 | 打开FACK拥塞避免和快速重传功能。(注意,当tcp_sack设置为0的时候,这个值即使设置为1也无效)[这个是TCP连接靠谱的核心功能] |
| tcp_dsack | 1 | 1 | 允许TCP发送”两个完全相同”的SACK。 |
| tcp_ecn | 0 | 0 | TCP的直接拥塞通告功能。 |
| tcp_reordering | 3 | 6 | TCP流中重排序的数据报最大数量。 (一般有看到推荐把这个数值略微调整大一些,比如5) |
| tcp_retrans_collapse | 1 | 0 | 对于某些有bug的打印机提供针对其bug的兼容性。(一般不需要这个支持,可以关闭它) |
| tcp_wmem:mindefaultmax | 4096
16384 131072 |
8192
131072 16777216 |
发送缓存设置
min:为TCP socket预留用于发送缓冲的内存最小值。每个tcp socket都可以在建议以后都可以使用它。默认值为4096(4K)。 default:为TCP socket预留用于发送缓冲的内存数量,默认情况下该值会影响其它协议使用的net.core.wmem_default 值,一般要低于net.core.wmem_default的值。默认值为16384(16K)。 max: 用于TCP socket发送缓冲的内存最大值。该值不会影响net.core.wmem_max,”静态”选择参数SOSNDBUF则不受该值影响。默认值为131072(128K)。(对于服务器而言,增加这个参数的值对于发送数据很有帮助,在我的网络环境中,修改为了51200 131072 204800) |
| tcprmem:mindefaultmax | 4096
87380 174760 |
32768
131072 16777216 |
接收缓存设置
同tcp_wmem |
| tcp_mem:mindefaultmax | 根据内存计算 | 786432
1048576 1572864 |
low:当TCP使用了低于该值的内存页面数时,TCP不会考虑释放内存。即低于此值没有内存压力。(理想情况下,这个值应与指定给 tcp_wmem 的第 2 个值相匹配 – 这第 2 个值表明,最大页面大小乘以最大并发请求数除以页大小 (131072 300 / 4096)。 )
pressure:当TCP使用了超过该值的内存页面数量时,TCP试图稳定其内存使用,进入pressure模式,当内存消耗低于low值时则退出pressure状态。(理想情况下这个值应该是 TCP 可以使用的总缓冲区大小的最大值 (204800 300 / 4096)。 ) high:允许所有tcp sockets用于排队缓冲数据报的页面量。(如果超过这个值,TCP 连接将被拒绝,这就是为什么不要令其过于保守 (512000 300 / 4096) 的原因了。 在这种情况下,提供的价值很大,它能处理很多连接,是所预期的 2.5 倍;或者使现有连接能够传输 2.5 倍的数据。 我的网络里为192000 300000 732000) 一般情况下这些值是在系统启动时根据系统内存数量计算得到的。 |
| tcp_app_win | 31 | 31 | 保留max(window/2^tcp_app_win, mss)数量的窗口由于应用缓冲。当为0时表示不需要缓冲。 |
| tcp_adv_win_scale | 2 | 2 | 计算缓冲开销bytes/2^tcp_adv_win_scale(如果tcp_adv_win_scale > 0)或者bytes-bytes/2^(-tcp_adv_win_scale)(如果tcp_adv_win_scale BOOLEAN>0) |
| tcp_low_latency | 0 | 0 | 允许 TCP/IP 栈适应在高吞吐量情况下低延时的情况;这个选项一般情形是的禁用。(但在构建Beowulf 集群的时候,打开它很有帮助) |
| tcp_westwood | 0 | 0 | 启用发送者端的拥塞控制算法,它可以维护对吞吐量的评估,并试图对带宽的整体利用情况进行优化;对于 WAN 通信来说应该启用这个选项。 |
| tcp_bic | 0 | 0 | 为快速长距离网络启用 Binary Increase Congestion;这样可以更好地利用以 GB 速度进行操作的链接;对于 WAN 通信应该启用这个选项。 |
| ip_forward | 0 | - | NAT必须开启IP转发支持,把该值写1 |
| ip_local_port_range:minmax | 32768
61000 |
1024
65000 |
表示用于向外连接的端口范围,默认比较小,这个范围同样会间接用于NAT表规模。 |
| ip_conntrack_max | 65535 | 65535 | 系统支持的最大ipv4连接数,默认65536(事实上这也是理论最大值),同时这个值和你的内存大小有关,如果内存128M,这个值最大8192,1G以上内存这个值都是默认65536 |
所处目录/proc/sys/net/ipv4/netfilter/
文件需要打开防火墙才会存在
| 名称 | 默认值 | 建议值 | 描述 |
| ip_conntrack_max | 65536 | 65536 | 系统支持的最大ipv4连接数,默认65536(事实上这也是理论最大值),同时这个值和你的内存大小有关,如果内存128M,这个值最大8192,1G以上内存这个值都是默认65536,这个值受/proc/sys/net/ipv4/ip_conntrack_max限制 |
| ip_conntrack_tcp_timeout_established | 432000 | 180 | 已建立的tcp连接的超时时间,默认432000,也就是5天。影响:这个值过大将导致一些可能已经不用的连接常驻于内存中,占用大量链接资源,从而可能导致NAT ip_conntrack: table full的问题。建议:对于NAT负载相对本机的 NAT表大小很紧张的时候,可能需要考虑缩小这个值,以尽早清除连接,保证有可用的连接资源;如果不紧张,不必修改 |
| ip_conntrack_tcp_timeout_time_wait | 120 | 120 | time_wait状态超时时间,超过该时间就清除该连接 |
| ip_conntrack_tcp_timeout_close_wait | 60 | 60 | close_wait状态超时时间,超过该时间就清除该连接 |
| ip_conntrack_tcp_timeout_fin_wait | 120 | 120 | fin_wait状态超时时间,超过该时间就清除该连接 |
文件所处目录/proc/sys/net/core/
| 名称 | 默认值 | 建议值 | 描述 |
| netdev_max_backlog | 1024 | 16384 | 每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目,对重负载服务器而言,该值需要调高一点。 |
| somaxconn | 128 | 16384 | 用来限制监听(LISTEN)队列最大数据包的数量,超过这个数量就会导致链接超时或者触发重传机制。
web应用中listen函数的backlog默认会给我们内核参数的net.core.somaxconn限制到128,而nginx定义的NGX_LISTEN_BACKLOG默认为511,所以有必要调整这个值。对繁忙的服务器,增加该值有助于网络性能 |
| wmem_default | 129024 | 129024 | 默认的发送窗口大小(以字节为单位) |
| rmem_default | 129024 | 129024 | 默认的接收窗口大小(以字节为单位) |
| rmem_max | 129024 | 873200 | 最大的TCP数据接收缓冲 |
| wmem_max | 129024 | 873200 | 最大的TCP数据发送缓冲 |
生产中常用的参数:
[code lang=”bash”]
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl =15
net.ipv4.tcp_retries2 = 5
net.ipv4.tcp_fin_timeout = 2
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_orphans = 32768
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_wmem = 8192 131072 16777216
net.ipv4.tcp_rmem = 32768 131072 16777216
net.ipv4.tcp_mem = 786432 1048576 1572864
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.ip_conntrack_max = 65536
net.ipv4.netfilter.ip_conntrack_max=65536
net.ipv4.netfilter.ip_conntrack_tcp_timeout_established=180
net.core.somaxconn = 16384
net.core.netdev_max_backlog = 16384
[/code]
不同的生产环境需要优化的参数基本差不多,只是值有相应的变化。具体优化值要参考应用场景,这儿所列只是常用优化参数,是否适合,可在上面查看该参数描述,理解后,再根据自己生产环境而设。
其它相关linux内核参数调整文章:
Linux内核参数优化
http://flandycheng.blog.51cto.com/855176/476769
优化linux的内核参数来提高服务器并发处理能力
http://www.ha97.com/4396.html
nginx做web服务器linux内核参数优化
http://blog.csdn.net/force_eagle/article/details/6725243
sudops网站提供的优化例子:
Linux下TCP/IP及内核参数优化有多种方式,参数配置得当可以大大提高系统的性能,也可以根据特定场景进行专门的优化,如TIME_WAIT过高,DDOS攻击等等。
如下配置是写在sysctl.conf中,可使用sysctl -p生效,文中附带了一些默认值和中文解释(从网上收集和翻译而来),确有些辛苦,转载请保留链接,谢谢~。
相关参数仅供参考,具体数值还需要根据机器性能,应用场景等实际情况来做更细微调整。
[code lang=”bash”]
net.core.netdev_max_backlog = 400000
#该参数决定了,网络设备接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.core.optmem_max = 10000000
#该参数指定了每个套接字所允许的最大缓冲区的大小
net.core.rmem_default = 10000000
#指定了接收套接字缓冲区大小的缺省值(以字节为单位)。
net.core.rmem_max = 10000000
#指定了接收套接字缓冲区大小的最大值(以字节为单位)。
net.core.somaxconn = 100000
#Linux kernel参数,表示socket监听的backlog(监听队列)上限
net.core.wmem_default = 11059200
#定义默认的发送窗口大小;对于更大的 BDP 来说,这个大小也应该更大。
net.core.wmem_max = 11059200
#定义发送窗口的最大大小;对于更大的 BDP 来说,这个大小也应该更大。
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.default.rp_filter = 1
#严谨模式 1 (推荐)
#松散模式 0
net.ipv4.tcp_congestion_control = bic
#默认推荐设置是 htcp
net.ipv4.tcp_window_scaling = 0
#关闭tcp_window_scaling
#启用 RFC 1323 定义的 window scaling;要支持超过 64KB 的窗口,必须启用该值。
net.ipv4.tcp_ecn = 0
#把TCP的直接拥塞通告(tcp_ecn)关掉
net.ipv4.tcp_sack = 1
#关闭tcp_sack
#启用有选择的应答(Selective Acknowledgment),
#这可以通过有选择地应答乱序接收到的报文来提高性能(这样可以让发送者只发送丢失的报文段);
#(对于广域网通信来说)这个选项应该启用,但是这会增加对 CPU 的占用。
net.ipv4.tcp_max_tw_buckets = 10000
#表示系统同时保持TIME_WAIT套接字的最大数量
net.ipv4.tcp_max_syn_backlog = 8192
#表示SYN队列长度,默认1024,改成8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_syncookies = 1
#表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_timestamps = 1
#开启TCP时间戳
#以一种比重发超时更精确的方法(请参阅 RFC 1323)来启用对 RTT 的计算;为了实现更好的性能应该启用这个选项。
net.ipv4.tcp_tw_reuse = 1
#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1
#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout = 10
#表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。
net.ipv4.tcp_keepalive_time = 1800
#表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为30分钟。
net.ipv4.tcp_keepalive_probes = 3
#如果对方不予应答,探测包的发送次数
net.ipv4.tcp_keepalive_intvl = 15
#keepalive探测包的发送间隔
net.ipv4.tcp_mem
#确定 TCP 栈应该如何反映内存使用;每个值的单位都是内存页(通常是 4KB)。
#第一个值是内存使用的下限。
#第二个值是内存压力模式开始对缓冲区使用应用压力的上限。
#第三个值是内存上限。在这个层次上可以将报文丢弃,从而减少对内存的使用。对于较大的 BDP 可以增大这些值(但是要记住,其单位是内存页,而不是字节)。
net.ipv4.tcp_rmem
#与 tcp_wmem 类似,不过它表示的是为自动调优所使用的接收缓冲区的值。
net.ipv4.tcp_wmem = 30000000 30000000 30000000
#为自动调优定义每个 socket 使用的内存。
#第一个值是为 socket 的发送缓冲区分配的最少字节数。
#第二个值是默认值(该值会被 wmem_default 覆盖),缓冲区在系统负载不重的情况下可以增长到这个值。
#第三个值是发送缓冲区空间的最大字节数(该值会被 wmem_max 覆盖)。
net.ipv4.ip_local_port_range = 1024 65000
#表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为1024到65000。
net.ipv4.netfilter.ip_conntrack_max=204800
#设置系统对最大跟踪的TCP连接数的限制
net.ipv4.tcp_slow_start_after_idle = 0
#关闭tcp的连接传输的慢启动,即先休止一段时间,再初始化拥塞窗口。
net.ipv4.route.gc_timeout = 100
#路由缓存刷新频率,当一个路由失败后多长时间跳到另一个路由,默认是300。
net.ipv4.tcp_syn_retries = 1
#在内核放弃建立连接之前发送SYN包的数量。
net.ipv4.icmp_echo_ignore_broadcasts = 1
# 避免放大攻击
net.ipv4.icmp_ignore_bogus_error_responses = 1
# 开启恶意icmp错误消息保护
net.inet.udp.checksum=1
#防止不正确的udp包的攻击
net.ipv4.conf.default.accept_source_route = 0
#是否接受含有源路由信息的ip包。参数值为布尔值,1表示接受,0表示不接受。
#在充当网关的linux主机上缺省值为1,在一般的linux主机上缺省值为0。
#从安全性角度出发,建议你关闭该功能。
[/code]
最初的幸福ever也提供了一些参数的说明。
/proc/sys/net目录
所有的TCP/IP参数都位于/proc/sys/net目录下(请注意,对/proc/sys/net目录下内容的修改都是临时的,任何修改在系统重启后都会丢失),例如下面这些重要的参数:
安装可参考:https://docs.microsoft.com/zh-cn/sql/linux/sql-server-linux-setup-red-hat
1.下载sql server的源,便于通过yum命令来安装
curl https://packages.microsoft.com/config/rhel/7/mssql-server.repo > /etc/yum.repos.d/mssql-server.repo
2.安装
yum install -y mssql-server
3.配置
sqlservr-setup 或 mssql-conf setup
安装客户端工具
可以参考:https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-setup-tools
1.设置防火墙
要连接数据库,首先要打开防火墙上1433端口,也就是,增加tcp端口1433到公共区域,并且永久生效
2.下载客户端工具的源
curl https://packages.microsoft.com/config/rhel/7/prod.repo > /etc/yum.repos.d/msprod.repo
3.安装客户端工具
yum install mssql-tools unixODBC-devel
4.连接sql sever
sqlcmd -S localhost -U sa
you must configure in a separate build directory
必须在单独的生成目录中配置
当编译glibc 2.14 时候会出现上面的问题
只要新建一个文件夹,使用绝对路径编译就可以了
WordPress更新或是上传插件或主题错误时出现“无法安装这个包。PCLZIP_ERR_MISSING_FILE (-4) : Missing archive file”错误在某些配置不够完善的主机中可能会出现这种情况。这是因为空间中temp目录没有设置访问权限的问题,需要空间商为你设置目录访问权限,一般这种要求他们是不会理的,所以我们只能改变WordPress的上传临时目录。
解决方法如下:
1. 通过网站FTP打开WordPress根目录下的 wp-config.php 文件,找到如下代码:
/** WordPress 目录的绝对路径。 */
if ( !defined('ABSPATH') )
define('ABSPATH', dirname(__FILE__) . '/');
2. 在下面增加如下代码即可:
/** 指定WordPress的临时目录 */
define('WP_TEMP_DIR', ABSPATH . 'wp-content/temp');
3. 最后在 /wp-content/ 文件夹下新建个一个名为 temp 的文件夹,然后再重新上传或者更新下载插件和主题就可以了。
最好叫 temp 权限和系统中一致为777
 在发布最后一个维护版本更新之后,Linux 稳定版内核维护者 Greg Kroah-Hartman 宣布 Linux Kernel 3.18 分支走到了生命的尽头。而 3.18 LTS 原计划于今年 1 月终止支持。
在发布最后一个维护版本更新之后,Linux 稳定版内核维护者 Greg Kroah-Hartman 宣布 Linux Kernel 3.18 分支走到了生命的尽头。而 3.18 LTS 原计划于今年 1 月终止支持。
Linux Kernel 3.18.48 LTS 是该分支的最后版本,根据短日志显示该版本共计调整了 50 个文件,插入 159 处删除 351 处。升级网络堆栈的同时改善了 Bluetooth, Bridge, IPv4, IPv6, CAIF 和 Netfilter,并升级了 USB, SCSI, ATA, media, GPU, ATM, HID, MTD, SPI 和网络(有线和无线)驱动。新发布的 3.18.48 还修正了 3.18.47 和 3.18.27 中的一个 bug。
LTS 版通常会提供大约两年的支持时间,3.18 是在 2014 年 12 月发布的。如果你当前还在使用该内核分支,那么现在你应该升级至更新的 LTS 版本,例如 Linux Kernel 4.9 或者 4.4,这两个版本要比 3.18 更加的安全和强悍。不过 Linux Kernel 3.18 主要被 Google 和其他供应商应用于一些 Android 设备、部分 Chromebook 上,Kroah-Hartman 建议用户拒绝购买仍然使用 3.18 LTS 的供应商的设备。如果无法升级内核开发者也提供了一些建议。
“如果你在使用 Linux Kernel 3.18 中有困难,那么我可以给你提供一些帮助。首先,你需要和硬件供应商反馈,要求尽快升级否则不再购买他们的产品。如果供应商还是不升级,请致信我们让我们出面和厂商进行沟通,出现这个问题的肯定不止你一个人。”
来源:http://www.oschina.net/news/81799/linux-kernel-3-18-48-released
java -jar 运行应用,在刚发布时的时候一切都很正常,在运行一段时间后就出现CPU占用很高的问题,基本上是负载一天比一天高。
问题分析:
1,程序属于CPU密集型,和开发沟通过,排除此类情况。
2,程序代码有问题,出现死循环,或是死锁, 可能性极大。
过程:
1.代码是不能定位,从日志上也无法分析得出。
2.top,发现PID,83021 的Java进程占用CPU高达900%,出现故障。
3.找到该进程后,如何定位具体线程或代码呢,首先显示线程列表,并按照CPU占用高的线程排序:ps -mp 83021 -o THREAD,tid,time | sort -rn | head -n 10
USER %CPU PRI SCNT WCHAN USER SYSTEM TID TIME
ubox 88.9 19 – futex_ – – 83032 08:21:49
ubox 88.9 19 – – – – 83031 08:21:49
ubox 88.9 19 – – – – 83030 08:21:49
ubox 88.9 19 – – – – 83028 08:21:49
ubox 88.9 19 – – – – 83027 08:21:49
ubox 88.9 19 – – – – 83025 08:21:49
ubox 88.9 19 – – – – 83024 08:21:49
ubox 88.9 19 – – – – 83023 08:21:49
ubox 712 – – – – – – 2-18:57:53
找到了耗时最高的线程83032,占用CPU时间超过8小时了!
4.将需要的线程ID转换为16进制格式:
printf “%x\n” 83032
14458
5.最后打印线程的堆栈信息:jstack 83021 | grep 14458 -A 5
6.将输出的信息给开发部进行确认,这样就能找出有问题的代码。
通过最近几天的监控,CPU已经安静下来了。
2016年只剩下不到一个月的时间了, IT 界最重要的莫过于各种排行榜,除了加班最狠、待遇最好、妹子最多……的 IT 公司外,程序员们最关心的是不是各种编程语言、数据库的排行榜里,PHP 是最好的编程语言还是最好的“数据库”?
C 语言自 2015 年 11 月以来就有下降趋势。在今年之前的整个 15 年的时间内,其评分都在 15%-20% 之间波动,但今年却一反常态,评分跌至 10% 以下,并且没有看到回升的势头。C 语言到底发生了什么?为何一蹶不振?
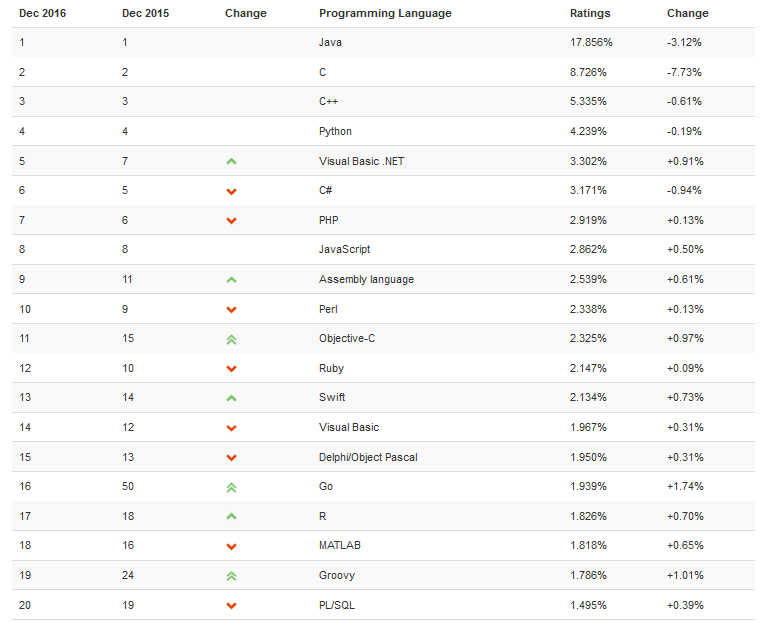
看来 Java 坐稳 2017 年热门编程语言排行榜冠军宝座了,你的语言上榜没?冠军总是比较忙,这会正和 Kotlin 比编译速度,到底谁更快呢~
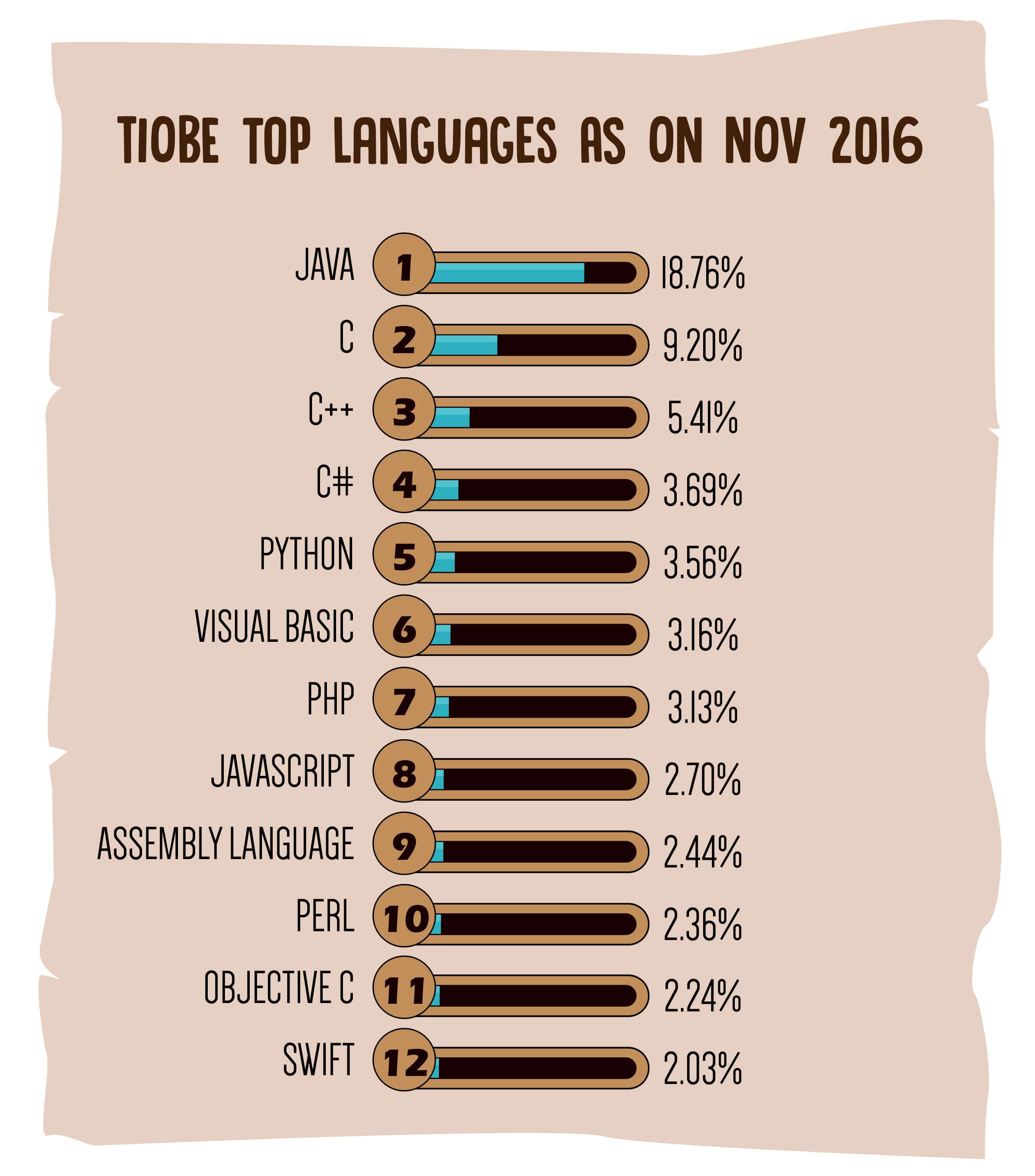
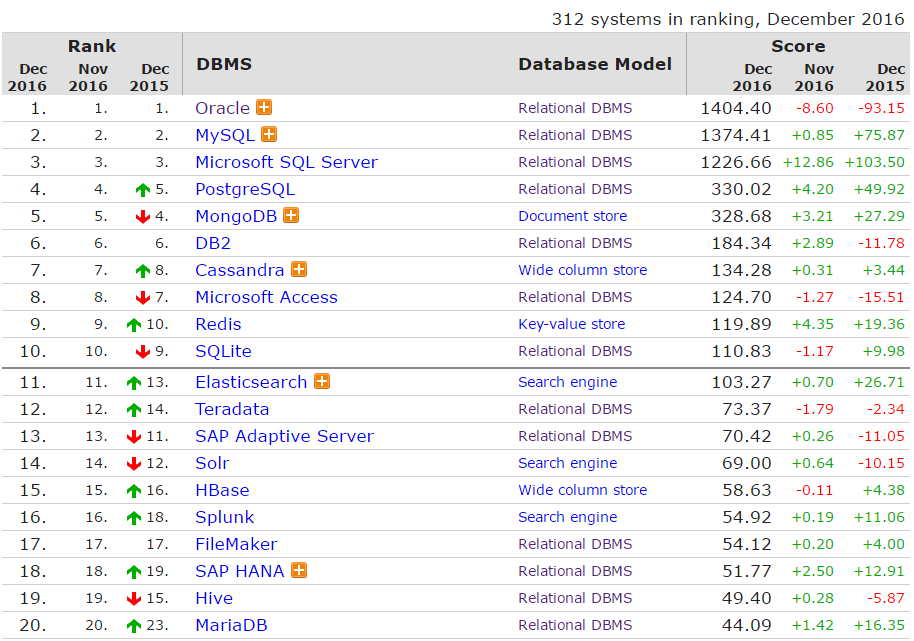
除了编程语言,2016 年全球数据库排名也尘埃落定,Oracle 、MySQL 和 Microsoft SQL Server 依然稳坐三甲宝座,不过,Oracle 的地位可就没那么稳固了,跟第二名 MySQL 的差距已缩小至 30 分!看来明年的排行榜有看头了,不知道是@美国网友:”php是世界上最好的数据库“,还是@凡行:“MySQL是世界上最好的编程语言!”说得对呢~@达尔文:”前排出售小板凳。”
同样地位不保的还有第三方 Android 系统 CM 之父,被踢出局的他与乔布斯经历了同样的悲惨境遇,作为 Cyanogen 公司的主要创始人,Steve Kondik 已经从这家公司离职。

这种感觉就像 Firebug 在其官方网站上宣布 —— “Firebug 扩展不再进行开发或维护,我们邀请您使用 Firefox 的内置开发工具以代替”。@世尘悉洞 :“回想起用firebug的岁月,挺伤感的。感谢一路陪伴,虽然现在不怎么使用了,但是还是很感谢之前的陪伴。”讲不出的再见~
虽然开发者的世界少了 Firebug,不过我们的大谷歌回归啦,Google Developers 中国网站正式发布!Google Developers 中国网站是特别为中国开发者而建立的,它汇集了 Google 为全球开发者所提供的开发技术资源,包括 API 文档、开发案例、技术培训的视频。并涵盖了以下关键开发技术和平台产品的信息:

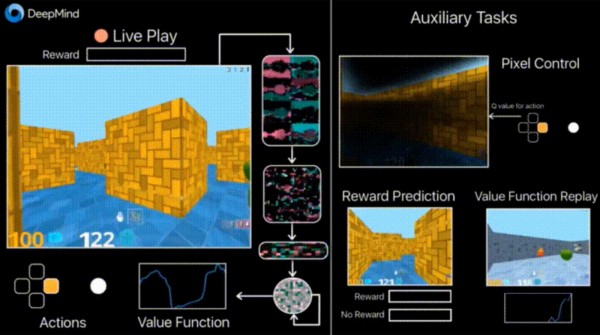
除了面向中国开发者的 Google Developers 中国网站,谷歌 DeepMind 还面向公众和开发者开放开源 AI 训练平台 DeepMind Lab,这款软件本周在GitHub上线,它看起来像一款卡通视频游戏,但却是精心设计的,目的是让AI开发者对他们机器人的学习加以控制。
当越来越牛逼的机器人取代程序员写代码,会发生什么呢?过去,程序员需要在大学或工作中花费好几年时间才能学习掌握一些编程知识,熟悉了解一些昂贵的服务器性能,而现在,只需几周时间就能搞定一项网页开发编程语言了。基于人工智能生成的代码,为整个行业带来了颠覆创新。

Nginx通过FastCGI运行PHP比Apache包含PHP环境有明显的优势,最近有消息称,PHP5.4将很有可能把PHP-FPM补丁包含在内核里,nginx服务器平台上运行PHP将更加轻松,下面我们就来看一篇php-fpm平滑启动并配置服务例子。
我的PHP是源码安装的。php-fpm在PHP 5.3.2以后的版本不支持以前的php-fpm (start|restart|stop|reload) ,那么如果将php-fpm配置成服务,并添加平滑启动/重启。
配置php-fpm.conf(vi php-7.1.0/etc/php-fpm.conf),将pid(;pid = run/php-fpm.pid)前的;去掉。
因为编译安装php的,所以会在php目录生成很多二进制文件,找到init.d.php-fpm,拷贝到init.d下。
cp php-7.1.0/sapi/fpm/init.d.php-fpm /etc/init.d/php-fpm
设置权限,并添加服务
chmod +x /etc/init.d/php-fpm
chkconfig –add php-fpm
以后可以使用如下命令管理php-fpm了
service php-fpm status
service php-fpm start
service php-fpm restart
service php-fpm reload
service php-fpm stop
英文:http://bigocheatsheet.com/
编译:Linux中国
链接:https://linux.cn/article-7480-1.html
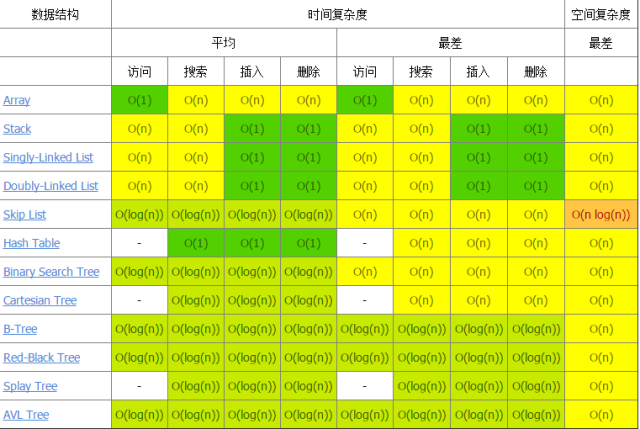
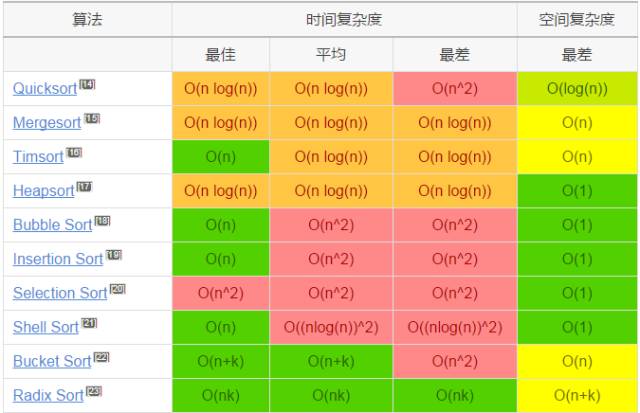
这篇文章覆盖了计算机科学里面常见算法的时间和空间的大 OBig-O 复杂度。我之前在参加面试前,经常需要花费很多时间从互联网上查找各种搜索和排序算法的优劣,以便我在面试时不会被问住。最近这几年,我面试了几家硅谷的初创企业和一些更大一些的公司,如 Yahoo、eBay、LinkedIn 和 Google,每次我都需要准备这个,我就在问自己,“为什么没有人创建一个漂亮的大 O 速查表呢?”所以,为了节省大家的时间,我就创建了这个,希望你喜欢!
— Eric[1]

图例
数据结构操作
数组排序算法
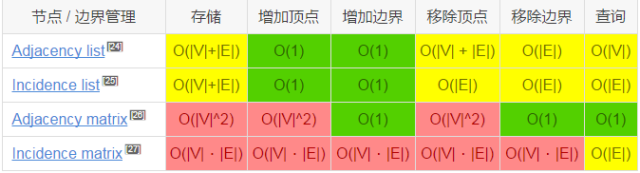
图操作
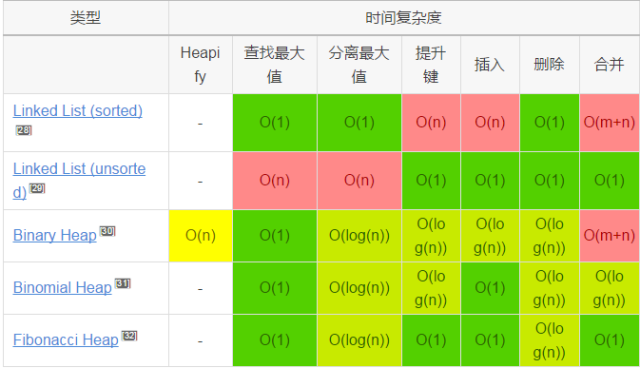
堆操作
大 O 复杂度图表
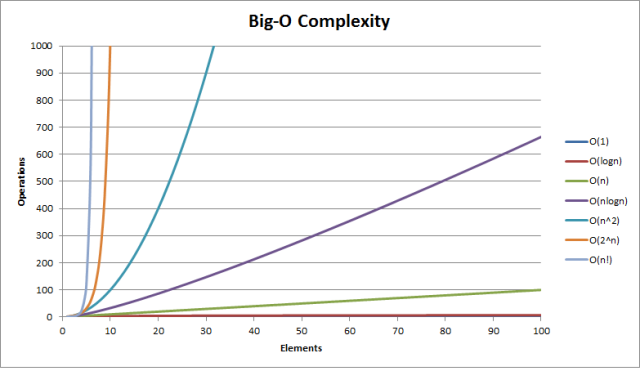
Big O 复杂度
推荐阅读
关注「算法爱好者」
2015年,不管在企业市场还是个人消费市场都是 Linux非常重要的一年。作为一个自2005年起就开始使用 Linux的 Linuxer ,我门见证了 Linux在过去十年的成长。2016 Linux 将更加精彩,所以我们选择了一些大放异彩的发行版。现在 Linux Story小编就带你去领略一下各领域的风采吧!
最好的回归发行版:openSUSE
openSUSE 背后的 SUSE 公司是最老的 Linux 企业,它成立于 Linus Torvalds 宣布放出 Linux 的一年后。它其实早于 Red Hat 的诞生,它也是社区主导的发行版 openSUSE 的赞助商。
在2015,openSUSE 团队决定靠拢 SUSE Linux 企业版(SLE)以便用户可以共享企业服务版本的 DNA ,就像 CentOS 和 Ubuntu一样。之后,openSUSE 变成了 openSUSE Leap,直接基于 SLESP1 。这两个发行版将共享代码库以互惠互利,SUSE 将吸取 openSUSE 的优秀内容,反之亦然。通过这一举措,openSUSE 也抛弃了常规的发行周期,一个新的版本将和 SLE 保持一致。这意味着每个版本将有更长的生命周期。这一举措的结果是 openSUSE 将变成一个非常重要的发行版,因为潜在的 SLE 用户可以使用 openSUSE Leap。然而,这还不是全部,openSUSE 同时发布了一个纯粹的滚动发行版—— Tumbleweed 。可以参考Linux Story闻其详撰写的这篇文章《生命、宇宙以及Linux 系统的终极答案? openSUSE Leap 42.1 华丽发布》,所以现在用户可以使用超稳定的 openSUSE Leap和 始终保持最新的 openSUSE Tumbleweed。

在我记忆中没有其他发行版做了如此深刻的回归。
最可定制的发行版: Arch Linux
Arch Linux是现阶段最好的滚动发行版,好吧,我可能因为我是 Arch Linux用户而产生了偏见。更重要的是 Arch 在其他方面也表现良好,这也是为什么我选择它作为我的操作系统的原因。
Arch Linux 是一个为那些想了解 Linux 一切的人准备的发行版,因为你必须手动安装一切,它会让你学会基于 Linux 的操作系统的每个部分。Arch Linux 是最可定制的发行版,你获得的只是一个基础系统,然后你可以在它上面建立属于你个人的发行版。不论好坏,它都不像 openSUSE 和 Ubuntu,它没有额外的补丁和整合内容,你甚至可以获得上游开发者创建的内容。Arch Linux 也是最好的滚动发行版之一。他总是更新,用户始终使用最新的软件包,并且他们还可以通过稳定的存储库运行预发布软件。Arch 也因优异的文档闻名。 Arch Wiki 可以让我得到任何 Linux 相关的资料。Arch 中我最喜欢的内容是它提供的所有的包和软件都可在“任何” Linux 发行版上运行。感谢 Arch User Repository(AUR)。
最好看的发行版:elementary OS
不同的 Linux 发行版有不同的侧重点,在大多数情况下这都是技术差异。在很多 Linux 发行版中外观和感觉是无足轻重的——更像是一个边缘项目。不管什么角度,Linux Story 一直觉得它是一个非常漂亮的系统。

elementary OS正试图改变这一切。在它里面,设计走在了前列,其原因是很明显的。该发行版漂亮的图标是 Linux 世界闻名的设计师们设计开发的。elementary OS非常严格要求整体的外观和感觉。开发者已经创建了包括桌面环境在内的自己的组件,此外,他们只选择那些符合自己设计模式的应用程序。可以在该系统上看到 Mac OS X 的影子。
最佳新人:Solus
Solus操作系统最近已经获得了相当多的关注,它是一个从头开始创建的前瞻性操作系统。它并不是 Debian 或 Ubuntu的衍生物。它搭配了为集成 GNOME 从头开始构建的 Budgie 桌面环境。Solus 有和 Google Chrome OS相同的极简主义方法。Linux Story 完全认同 Solus 为最佳新人。

我没有使用太多 Solus,但它看起来很有希望。 Solus 不是一个“新的”操作系统,它曾经以不同的形式和名称存在。但是整个项目的新名称是在2015年才提出的。
最好的教育操作系统:ezgo Linux
ezgo是一套开源、公益、免费、面向教育的电脑操作系统,基于Linux 而开发,它包含有丰富的互动教学软件和开放教材、知识,涵盖了物理、化学、地理、天文、 生物、数学、计算机等学科,矢志帮助学校的学生和教师的教育信息化,帮助孩子们和家长、老师以最方便最有效的方式接触、获取全世界最先进的知识和智慧,这 是一个发源于台湾的开源项目,目前在国内是ezgo中国社区,重庆Linux用户组 ChongqingLUG 在维护、开发和推广。搜集了包括 PhET在内的大量开源教材,Linux Story 有幸也曾经报道过跟 ezgo 有关的消息,它的官方网站是 http://ezgolinux.org/。关心教育的家长、学生和老师值得关注。
最好的云操作系统:Chrome OS
Chrome OS不是一个典型的基于 Linux 的发行版,因为它是一个为在线活动设计的基于浏览器的操作系统。而且,由于它基于 Linux 同时它的源码是供所有人编译,所以它也很有吸引力。我每天都使用 Chrome OS ,这是一个对纯粹为网络活动而设计的极好的,免维护的,不断更新的操作系统。Chrome OS 和 Android 一起值得所有的新人来实现 PC 和其他平台的 Linux 普及。Linux Story 曾经也试用过 Acer Chromebook 11,感觉相当不错。

最好的笔记本操作系统:Ubuntu MATE
大多数笔记本没有非常高端的硬件,如果你正在运行一个非常消耗资源的桌面环境的话你将不会有太多的系统资源或电池续航来供你使用,因为系统已经占用了很多。这就是我发现为什么 Ubuntu MATE是一个优秀的操作系统。因为它是轻量级的,但也有应有尽有的内容给你提供不错的体验。正是由于它轻量级的设计,大部分的系统资源可供你去完成繁重的工作。我认为它在低端硬件上是一个真正优秀的发行版。

最好的旧硬件支持系统:Lubuntu
如果你有闲置的旧笔记本或者台式机,可以使用 Lubuntu来令它焕发生机。Lubuntu 使用 LXDE 桌面环境,但该项目已经和 Razor Qt 合并为 LXQt 项目了。尽管最新的15.04版本仍然使用 LXDE ,但是以后的版本将使用 LXQt 。Lubuntu 确实是一款适合旧硬件的操作系统。
最好的物联网操作系统:Snappy Ubuntu Core
Snappy Ubuntu Core是最好的物联网以及其他类似设备的基于 Linux 的操作系统。该操作系统有很大的潜力将近乎的所有东西都变成智能设备,比如路由器、咖啡机、无人驾驶飞机等等。优秀的软件管理和为增强安全性设计的容器化将它变得更加好玩。
最好的台式机操作系统:Linux Mint Cinnamon
Linux Mint Cinnamon是最好的台式机操作系统,它对硬件强大的笔记本也是最好的。我将它当成 Linux 世界的 Mac OS X 。老实说,我曾经因为 Cinnamon的不稳定而十分不愉快。但是,只要开发者选择 LTS 版本,它就变得难以置信的稳定。因为开发者不必花太多时间去跟上 Ubuntu,所以他们可以花更多时间去让 Cinnamon 更好。
最好的游戏系统:Steam OS
游戏一直是桌面版 Linux 的弱点,许多用户启动双系统的 Windows只是为了玩游戏。Valve Software 正在努力改变这一现状。Valve 是一个提供使游戏在不同平台上运行的客户端的游戏分销商。而且,为了创建基于 Linux 的游戏框架,Valve 已经创建了他们自己的开放式操作系统—— Steam OS。在2015年底,合作伙伴开始将 Steam 机器推向市场。

最好的隐私保护操作系统:Tails
当下大量的监视和营销者的跟踪(匿名跟踪的目标内容是可接受的)让隐私保护已经成为一个主要的问题。如果你的业务需要避免政府和营销机构的追踪,你就需要考虑一款从底层设计隐私保护的操作系统。
而且,在这一方面没有其他的能打败 Tails。它是基于 Debian 的设计用来实现隐私保护和匿名化的操作系统。Tails 非常棒,据报道,美国国家安全局(NSA)认为它是自己使命的重要威胁。
最好的多媒体制作系统:Ubuntu Studio
多媒体制作是基于 Linux 的操作系统的主要缺点之一,所有专业级的程序在 Windows和 Mac OS X 上都可找到。Linux 上却没有像样的音频/视频制作软件,但一个多媒体制作系统需要的不仅仅是像样的应用程序。它应该使用轻量级的桌面环境使宝贵的系统资源如 CPU、RAM 被系统尽量少的使用,以便用于多媒体制作程序。因此,最好的 Linux 多媒体制作系统是 Ubuntu Studio,它使用 Xfce 桌面环境并配备了众多的音频,视频和图像编辑应用程序。Linux Story 网站很长时间也用过它来制作一些影音多媒体素材。

最好的企业级系统:SLE/RHEL
企业用户不会四处寻找运行在自己服务器上的发行版。他们已经知道选择范围:Red Hat Enterprise Linux 或者 SUSE Linux Enterprise 。这两个名字已经成为企业级系统的代名词。这些公司也在设法在容器化和软件定义上的创新来推倒当前的壁垒。Linux Story 认为 RHEL 确实稳定,确实好用。
最好的服务器操作系统:Debian/CentOS
如果你正打算运行一个服务器,但是又不想为 RHEL 或 SLE 的维护付费,那么 Debian 或 CentOS 是你最好的选择。这些发行版是社区主导的服务器版本,它们有着黄金标准。而且,它们的支持周期很长,所以你不必担心经常升级系统。
最好的移动操作系统:Plasma Mobile
尽管基于 Linux 的操作系统—— Android 正在主宰移动领域,包括我在内的很多开源社区的成员仍然希望有一个发行版能够在移动设备上提供传统的 Linux 桌面应用程序。同时,它最好是由一个社区负责运营维护而不是一个公司以便让用户仍然是受关注的焦点,而不是以公司的财务目标为焦点。而这正是 KDE 的 Plasma Mobile带来的希望。
该版本是基于 Kubuntu 的,发布于2015年。因为 KDE 社区在公众环境中遵守标准和发展东西是众所周知的,所以我对 Plasma Mobile的未来充满希望。
最好的 ARM 设备发行版:Arch Linux ARM
随着 Android 的成功,我们已经被 ARM 设备所包围——从树莓派到 Chromebook 再到 Nvidia Shield。为 Intel/AMD 处理器编写的传统发行版将不能在这些设备上运行。虽然一些发行版专为 ARM 设计,但是大多数都只针对具体的硬件,比如为树莓派设计的 Raspbian 。这也是为什么 Arch Linux ARM(ALARM) 让人眼前一亮。因为它是一个纯粹由社区主导的基于 Arch Linux 的发行版,你可以在树莓派、Chromebook、Android 设备、Nvidia Shield 等上面运行它。这个发行版更有趣的是,因为 Arch User Repository(AUR)的原因,所以你可以安装许多你可能在其他发行版上无法获得的应用程序。
总结
当我完成这篇文章的时候我很惊讶和惊奇,非常令人兴奋的看到有适合每个人的 Linux 世界。如果这一年桌面版的 Linux 一直跳票也没关系,我们因 Linux 时刻高兴着!
下面给除了各linux发行版比较常用的系统信息查询的命令
# man # 使用man命令 查看命令手册
# uname -a # 查看内核/操作系统/CPU信息
# head -n 1 /etc/issue # 查看操作系统版本
# cat /proc/cpuinfo # 查看CPU信息
# hostname # 查看计算机名
# lspci -tv # 列出所有PCI设备
# lsusb -tv # 列出所有USB设备
# lsmod # 列出加载的内核模块
# env # 查看环境变量资源
# free -m # 查看内存使用量和交换区使用量
# df -h # 查看各分区使用情况
# du -sh <目录名> # 查看指定目录的大小
# grep MemTotal /proc/meminfo # 查看内存总量
# grep MemFree /proc/meminfo # 查看空闲内存量
# uptime # 查看系统运行时间、用户数、负载
# cat /proc/loadavg # 查看系统负载磁盘和分区
# mount | column -t # 查看挂接的分区状态
# fdisk -l # 查看所有分区
# swapon -s # 查看所有交换分区
# hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
# dmesg | grep IDE # 查看启动时IDE设备检测状况网络
# ifconfig # 查看所有网络接口的属性
# iptables -L # 查看防火墙设置
# route -n # 查看路由表
# netstat -lntp # 查看所有监听端口
# netstat -antp # 查看所有已经建立的连接
# netstat -s # 查看网络统计信息进程
# ps -ef # 查看所有进程
# top # 实时显示进程状态用户
# w # 查看活动用户
# id <用户名> # 查看指定用户信息
# last # 查看用户登录日志
# cut -d: -f1 /etc/passwd # 查看系统所有用户
# cut -d: -f1 /etc/group # 查看系统所有组
# crontab -l # 查看当前用户的计划任务服务
# chkconfig –list # 列出所有系统服务
# chkconfig –list | grep on # 列出所有启动的系统服务程序
# rpm -qa # 查看所有安装的软件包
最近常出现 客户端连接远程服务器失败问题
show processlist;
出现 unauthenticated user,一直到超时;
网上查了下,到处都是互相抄袭文章,类似:
解决的方案很简单,结束这个反查的过程,禁止任何解析。
打开mysql的配置文件(my.cnf),在[mysqld]下面增加一行:
skip-name-resolve
。。。
实际上我都用IP连接的,不会出现这种问题
最后网上有个说是网络慢也会影响连接,ping 测试了下果然慢
ping liyunde.com
PING liyunde.com (112.126.64.59): 56 data bytes
64 bytes from 112.126.64.59: icmp_seq=0 ttl=51 time=41.072 ms
64 bytes from 112.126.64.59: icmp_seq=1 ttl=51 time=40.965 ms
64 bytes from 112.126.64.59: icmp_seq=2 ttl=51 time=41.036 ms
64 bytes from 112.126.64.59: icmp_seq=3 ttl=51 time=42.662 ms
64 bytes from 112.126.64.59: icmp_seq=4 ttl=51 time=41.681 ms
64 bytes from 112.126.64.59: icmp_seq=5 ttl=51 time=41.701 ms
64 bytes from 112.126.64.59: icmp_seq=6 ttl=51 time=41.859 ms
64 bytes from 112.126.64.59: icmp_seq=7 ttl=51 time=43.713 ms
网络响应过慢,配置服务器不能解决这个问题,换个好点的网络,问题自然解决。
https://kr.github.io/beanstalkd/
yum install beanstalkd --enablerepo=epel
/usr/bin/beanstalkd -l 0.0.0.0 -p 11300 -b /var/lib/beanstalkd/binlog -F
-b 开启binlog,断电后重启会自动恢复任务。
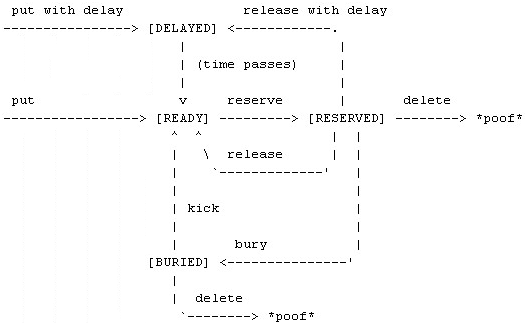
当producer直接put一个job时,job就处于READY状态,等待consumer来处理,如果选择延迟put,job就先到 DELAYED状态,等待时间过后才迁移到READY状态。consumer获取了当前READY的job后,该job的状态就迁移到RESERVED, 这样其他的consumer就不能再操作该job。
当consumer完成该job后,可以选择delete, release或者bury操作;delete之后,job从系统消亡,之后不能再获取;release操作可以重新把该job状态迁移回READY(也 可以延迟该状态迁移操作),使其他的consumer可以继续获取和执行该job;有意思的是bury操作,可以把该job休眠,等到需要的时候,再将休 眠的job kick回READY状态,也可以delete BURIED状态的job。
正是有这些操作和状态,才可以基于此做出很多意思的应用,比如要实现一个循环队列,就可以将RESERVED状态的 job休眠掉,等没有READY状态的job时再将BURIED状态的job一次性kick回READY状态。
任务 (job) 可以有 0~2^32 个优先级, 0 代表最高优先级,默认优先级为1024。
可以通过binlog将job及其状态记录到文件里面,在Beanstalkd下次启动时可以通过读取binlog来恢复之前的job及状态。
分布式设计和Memcached类似,beanstalkd各个server之间并不知道彼此的存在,都是通过client来实现分布式以及根据tube名称去特定server获取job。
为了防止某个consumer长时间占用任务但不能处理的情况,Beanstalkd为reserve操作设置了timeout时间,如果该consumer不能在指定时间内完成job,job将被迁移回READY状态,供其他consumer执行。
项目地址: https://github.com/pda/pheanstalk/
$pheanstalk = new Pheanstalk_Pheanstalk('127.0.0.1'); $pheanstalk ->useTube('tubeName') ->put($jobData);
$job = $pheanstalk ->watch('tubeName') ->ignore('default') ->reserve(); echo $job->getData(); $pheanstalk->delete($job);
$isAlive = $pheanstalk->getConnection()->isServiceListening(); //返回 true 或 false
try{ $tubeStatus = $pheanstalk->statsTube('tubeName'); } catch (Exception $e){ if($e->getMessage()=='Server reported NOT_FOUND'){ //tube 不存在 $current_jobs_ready = 0; } }
https://github.com/ptrofimov/beanstalk_console
https://chrome.google.com/webstore/detail/beanstalkd-dashboard/dakkekjnlffnecpmdiamebeooimjnipm