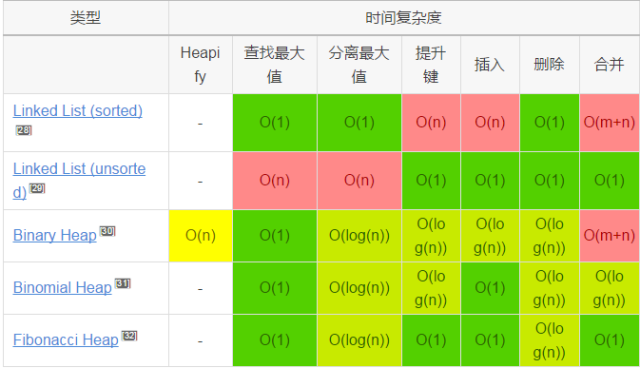
翻译:李伟
审校:张帆
译自:Github

任何一个版本控制系统中,最有用的特性之一莫过于 “撤销(undo)”操作。在Git中,“撤销”有很多种含义。
当你完成了一次新的提交(commit),Git会及时存储当前时刻仓库(repository)的快照(snapshot);你能够使用Git将项目回退到任何之前的版本。
下文中,我将列举几个常见的、需要“撤销”的场景,并且展示如何使用Git来完成这些操作。
一、撤销一个公共修改 Undo a “public” change
场景:你刚刚用git push将本地修改推送到了GitHub,这时你意识到在提交中有一个错误。你想撤销这次提交。
使用撤销命令:git revert
发生了什么:git revert将根据给定SHA的相反值,创建一个新的提交。如果旧提交是“matter”,那么新的提交就是“anti-matter”——旧提交中所有已移除的东西将会被添加进到新提交中,旧提交中增加的东西将在新提交中移除。
这是Git最安全、也是最简单的“撤销”场景,因为这样不会修改历史记录——你现在可以git push下刚刚revert之后的提交来纠正错误了。
二、修改最近一次的提交信息 Fix the last commit message
场景:你只是在最后的提交信息中敲错了字,比如你敲了git commit -m “Fxies bug #42″,而在执行git push之前你已经意识到你应该敲”Fixes bug #42″。
使用撤销命令:git commit –amend或git commit –amend -m “Fixes bug #42”
发生了什么:git commit –amend将使用一个包含了刚刚错误提交所有变更的新提交,来更新并替换这个错误提交。由于没有staged的提交,所以实际上这个提交只是重写了先前的提交信息。
三、撤销本地更改 Undo “local” changes
场景:当你的猫爬过键盘时,你正在编辑的文件恰好被保存了,你的编辑器也恰在此时崩溃了。此时你并没有提交过代码。你期望撤销这个文件中的所有修改——将这个文件回退到上次提交的状态。
使用撤销命令:git checkout —
发生了什么:git checkout将工作目录(working directory)里的文件修改成先前Git已知的状态。你可以提供一个期待回退分支的名字或者一个确切的SHA码,Git也会默认检出HEAD——即:当前分支的上一次提交。
注意:用这种方法“撤销”的修改都将真正的消失。它们永远不会被提交。因此Git不能恢复它们。此时,一定要明确自己在做什么!(或许可以用git diff来确定)
四、重置本地修改 Reset “local” changes
场景:你已经在本地做了一些提交(还没push),但所有的东西都糟糕透了,你想撤销最近的三次提交——就像它们从没发生过一样。
使用撤销命令:git reset或git reset –hard
发生了什么:git reset将你的仓库纪录一直回退到指定的最后一个SHA代表的提交,那些提交就像从未发生过一样。默认情况下,git reset会保留工作目录(working directory)。这些提交虽然消失了,但是内容还在磁盘上。这是最安全的做法,但通常情况是:你想使用一个命令来“撤销”所有提交和本地修改——那 么请使用–hard参数吧。
五、撤销本地后重做 Redo after undo “local”
场景:你已经提交了一些内容,并使用git reset –hard撤销了这些更改(见上面),突然意识到:你想还原这些修改!
使用撤销命令:git reflog和git reset, 或者git checkout
发生了什么:git reflog是一个用来恢复项目历史记录的好办法。你可以通过git reflog恢复几乎任何已提交的内容。
你或许对git log命令比较熟悉,它能显示提交列表。git reflog与之类似,只不过git reflog显示的是HEAD变更次数的列表。
一些说明:
1. 只有HEAD会改变。当你切换分支时,用git commit提交变更时,或是用git reset撤销提交时,HEAD都会改变。但当你用git checkout –时, HEAD不会发生改变。(就像上文提到的情形,那些更改根本就没有提交,因此reflog就不能帮助我们进行恢复了)
2. git reflog不会永远存在。Git将会定期清理那些“不可达(unreachable)”的对象。不要期望能够在reflog里找到数月前的提交记录。
3. reflog只是你个人的。你不能用你的reflog来恢复其他开发者未push的提交。

因此,怎样合理使用reflog来找回之前“未完成”的提交呢?这要看你究竟要做什么:
1. 如果你想恢复项目历史到某次提交,那请使用git reset –hard
2. 如果你想在工作目录(working direcotry)中恢复某次提交中的一个或多个文件,并且不改变提交历史,那请使用git checkout–
3. 如果你想确切的回滚到某次提交,那么请使用git cherry-pick。
六、与分支有关的那些事 Once more, with branching
场景:你提交了一些变更,然后你意识到你正在master分支上,但你期望的是在feature分支上执行这些提交。
使用撤销命令:git branch feature, git reset –hard origin/master, 和 git checkout feature
发生了什么:你可能用的是git checkout -b来建立新的分支,这是创建和检出分支的便捷方法——但实际你并不想立刻切换分支。git branch feature会建立一个叫feature的分支,这个分支指向你最近的提交,但是你还停留在master分支上。
git reset –hard将master回退至origin/master,并忽略所有新提交。别担心,那些提交都还保留在feature上。
最后,git checkout将分支切换到feature,这个分支原封不动的保留了你最近的所有工作。
七、事半功倍处理分支 Branch in time saves nine
场景:你基于master新建了一个feature分支,但是master分支远远落后与origin/master。现在master分支与origin/master同步了,你期望此刻能在feature下立刻commit代码,并且不是在远远落后master的情况下。
使用撤销命令:git checkout feature和git rebase master
发生了什么:你也许已经敲了命令:git reset(但是没用–hard,有意在磁盘上保存这些提交内容),然后敲了git checkout -b,之后重新提交更改,但是那样的话,你将失去本地的提交记录。不过,一个更好的方法:
使用git rebase master可以做到一些事情:
1.首先,它定位你当前检出分支和master之间的共同祖先节点(common ancestor)。
2.然后,它将当前检出的分支重置到祖先节点(ancestor),并将后来所有的提交都暂存起来。
3.最后,它将当前检出分支推进至master末尾,同时在master最后一次提交之后,再次提交那些在暂存区的变更。
八、批量撤销/找回 Mass undo/redo
场景:你开始朝一个既定目标开发功能,但是中途你感觉用另一个方法更好。你已经有十几个提交,但是你只想要其中的某几个,其他的都可以删除不要。
使用撤销命令:git rebase -i
发生了什么:-i将rebases设置为“交互模式(interactive mode)”。rebase开始执行的操作就像上文讨论的一样,但是在重新执行某个提交时,它会暂停下来,让你修改每一次提交。
rebase –i将会打开你的默认文本编辑器,然后列出正在执行的提交,就像这样:

前两列最关键:第一列是选择命令,它会根据第二列中的SHA码选择相应的提交。默认情况下,rebase –i会认为每个更改都正通过pick命令被提交。
要撤销一个提交,直接在编辑器删除对应的行就可以了。如果在你的项目不再需要这些错误的提交,你可以直接删除上图中的第1行和3-4行。
如 果你想保留提交但修改提交信息,你可以使用reword命令。即,将命令关键字pick换成reword(或者r)。你现在可能想立刻修改提交消息,但这 么做不会生效——rebase –i将忽略SHA列后的所有东西。现有的提交信息会帮助我们记住0835fe2代表什么。当你敲完rebase –i命令后,Git才开始提示你重写那些新提交消息。
如果你需要将2个提交合并,你可以用squash或者fixup命令,如下图:

squash和fixup都是“向上”结合的——那些用了这些合并命令(编者按:指squash、fixup)的提交,将会和它之前的提交合并:上图中,0835fe2和6943e85将会合并成一个提交,而38f5e4e和af67f82将会合并成另一个提交。
当 你用squash时,Git将会提示是否填写新的提交消息;fixup则会给出列表中第一个提交的提交信息。在上图中,af67f82是一个 “Ooops”信息,因为这个提交信息已经同38f5e4e一样了。但是你可以为0835fe2和6943e85合并的新提交编写提交信息。
当你保存并退出编辑器时,Git将会按照从上到下的顺序执行你的提交。你可以在保存这些提交之前,修改提交的执行顺序。如果有需要,你可以将af67f82和0835fe2合并,并且可以这样排序:

九、修复早先的提交 Fix an earlier commit
场景:之前的提交里落下了一个文件,如果先前的提交能有你留下的东西就好了。你还没有push,并且这个提交也不是最近的提交,因此你不能用commit –amend。
使用撤销命令:git commit –squash和git rebase –autosquash -i
发生了什么:git commit –squash将会创建一个新的提交,该提交信息可能像这样“squash! Earlier commit”。(你也可以手写这些提交信息,commit –squash只是省得让你打字了)。
如果你不想为合并的提交编写信息,也可以考虑使用命令git commit –fixup。这种情况下,你可能会使用commit –fixup,因为你仅希望在rebase中使用之前的提交信息。
rebase –autosquash –i将会启动rebase交互编辑器,编辑器会列出任何已完成的squash!和fixup!提交,如下图:

当 使用–squash和–fixup时,你或许记不清你想修复的某个提交的SHA码——只知道它可能在一个或五个提交之前。你或许可以使用Git的^和~ 操作符手动找回。HEAD^表示HEAD的前一次提交。HEAD~4表示HEAD前的4次提交,加起来总共是前5次提交。
十、停止跟踪一个已被跟踪的文件 Stop tracking a tracked file
场景:你意外将application.log添加到仓库中,现在你每次运行程序,Git都提示application.log中有unstaged的提交。你在.gitignore中写上”*.log”,但仍旧没用——怎样告诉Git“撤销”跟踪这个文件的变化呢?
使用撤销命令: git rm –cached application.log
发生了什么:尽 管.gitignore阻止Git跟踪文件的变化,甚至是之前没被跟踪的文件是否存在,但是,一旦文件被add或者commit,Git会开始持续跟踪这 个文件的变化。类似的,如果你用git add –f来“强制”add,或者覆盖.gitignore,Git还是会继续监视变化。所以以后最好不要使用–f来add .gitignore文件。
如果你希望移除那些应当被忽略的文件,git rm –cached可以帮助你,并将这些文件保留在磁盘上。因为这个文件现在被忽略了,你将不会在git status中看到它,也不会再把这个文件commit了。
以上就是如何在Git上撤销的方法。如果你想学习更多Git命令用法,可以移步下面相关的文档:
原文地址:Github
译文地址:http://www.jointforce.com/jfperiodical/article/show/796?m=d03